📝 Paper Summary
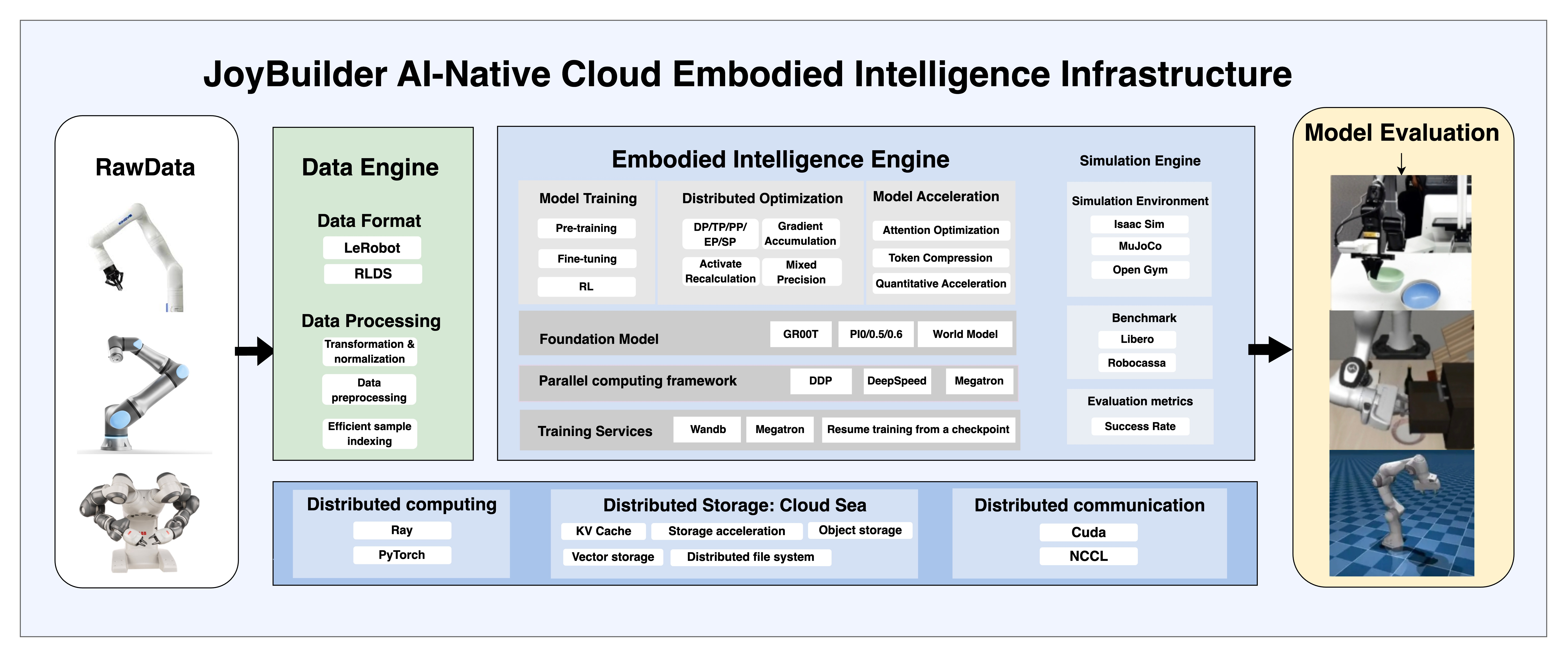
Embodied AI Infrastructure
Distributed Training
Reinforcement Learning Systems
This paper presents a cloud-native, thousand-GPU infrastructure for embodied AI that reduces training time by 40x through variable-length attention optimization, data packing, and a novel triple-level asynchronous reinforcement learning pipeline.
Core Problem
Training large-scale embodied models on thousand-GPU clusters faces bottlenecks in I/O blocking, inefficient attention padding, and resource idling caused by synchronous training dependencies.
Why it matters:
- Synchronous training pipelines leave expensive GPUs idle while waiting for environment interactions, limiting throughput
- Standard padding in multimodal attention (images/text) wastes significant compute and memory on invalid tokens
- Traditional data lakes struggle with the high concurrency and small-file demands of embodied data, blocking distributed training
Concrete Example:
In traditional training, a robot policy network must wait for all parallel simulation environments to finish a step before updating. If one environment lags, the entire cluster idles. Additionally, short text commands are padded to fixed lengths (e.g., 200 tokens), causing the model to process mostly empty data.
Key Novelty
RL-VLA3 Asynchronous Architecture & Data-Model Co-optimization
- Introduces RL-VLA3, a pipeline that completely decouples environment interaction (rollout) from model training (actor) using asynchronous queues, allowing continuous data generation and updates
- Implements 'Data Packing' and variable-length FlashAttention to stitch short multimodal samples into full sequences, eliminating padding waste
- Utilizes fine-grained block-wise FP8 quantization for VLA models to accelerate inference on edge devices
Architecture
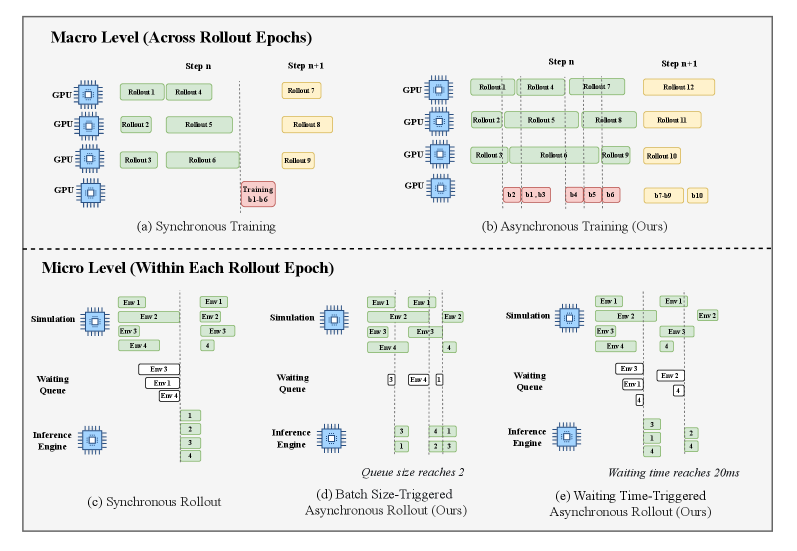
The RL-VLA3 triple-level asynchronous training architecture
Evaluation Highlights
- Reduced GR00T-N1.5 model single-round training time from 15 hours to 22 minutes (40x speedup) on thousand-GPU clusters
- Achieved 126.67% maximum throughput increase on the LIBERO benchmark using the RL-VLA3 asynchronous strategy compared to synchronous baselines
- Variable-length FlashAttention combined with Data Packing resulted in a 188% speed increase by eliminating sequence redundancy
Breakthrough Assessment
8/10
Strong engineering contribution demonstrating massive speedups (40x) and scalability (1000 GPUs) for embodied AI, addressing critical infrastructure bottlenecks.