📊 Experiments & Results
Evaluation Setup
In-context binary classification on dynamically generated Gaussian tasks
Benchmarks:
- Task A: Shifted Mean Discrimination (Linear classification with nuisance shift) [New]
- Task B: Variance Discrimination (Nonlinear (Quadratic) classification) [New]
Metrics:
- Accuracy (%)
- Pearson Correlation (r) with Oracle LLR
- Spearman Rank Correlation (ρ) with Oracle LLR
- Statistical methodology: Results reported over 3 random seeds with standard deviation.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of Transformer performance against the theoretical Bayes-optimal Oracle across linear and nonlinear tasks. | ||||
| Task B: Variance Discrimination | Accuracy | 84.0 | 83.0 | -1.0 |
| Task A: Shifted Mean | Accuracy | 84.6 | 78.3 | -6.3 |
| Task B: Variance Discrimination | Spearman Correlation (ρ) | 1.0 | 0.98 | -0.02 |
| Task A (Large Shift σ_k=9.0) | Pearson Correlation (r) | 0.86 | 0.567 | -0.293 |
Experiment Figures
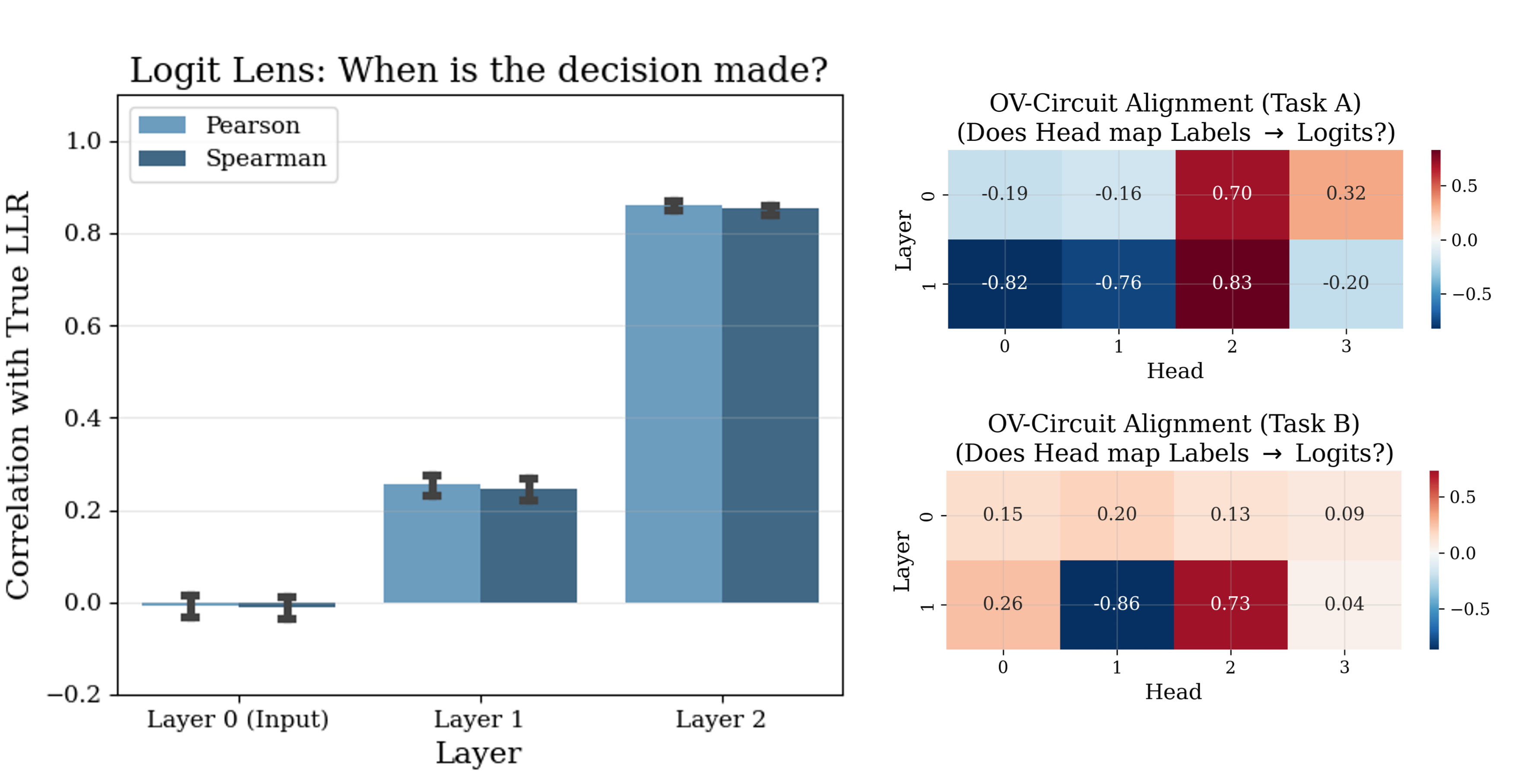
Logit Lens analysis showing the correlation of intermediate residual streams with the final target label across layers.
Cosine similarity of Attention Head Output-Value (OV) circuits with the final decision direction.
Main Takeaways
- Transformers can recover the sufficient statistics for likelihood-ratio tests from context, behaving like 'neural statisticians'.
- The model adapts its computational depth: Linear tasks utilize a shallow 'voting ensemble' (Layer 0 active), while nonlinear tasks require deeper sequential processing (Layer 1 active).
- While performance matches the oracle in nonlinear regimes, linear task performance suggests the model uses a noisy approximation rather than exact symbolic inference.
- The decision rule is not merely similarity-based (Nadaraya-Watson); it accounts for nuisance parameters like shifts ($k$) and variances.