📝 Paper Summary
Self-evolving Agentic reasoning
Linear memory
Agentic feedback mechanisms
A framework that analyzes agent execution histories to automatically extract and retrieve structured tips (strategies, recoveries, and optimizations) that prevent repeated errors and propagate efficient patterns.
Core Problem
LLM agents suffer from 'amnesia' due to statelessness; they repeatedly make the same errors, fail to reuse successful strategies, and cannot optimize inefficient but successful execution patterns across sessions.
Why it matters:
- Current agents struggle to adapt: an agent failing an API authentication today will likely fail again tomorrow without manual prompt engineering.
- Generic memory systems store conversational facts (e.g., user birthday) but fail to capture procedural execution logic (e.g., how to recover from a specific API error).
- Inefficiency propagates: agents may successfully complete tasks using redundant steps (e.g., looping vs. bulk operations) without ever learning the optimized approach.
Concrete Example:
In an e-commerce task, an agent might empty a cart by looping through `remove_item` calls instead of using `empty_cart`. Later, it might fail checkout due to a missing payment method, then recover. A standard agent forgets both the inefficiency and the recovery logic for the next run.
Key Novelty
Trajectory-Informed Procedural Memory
- Parses agent execution logs (thoughts + actions) to extract three specific types of guidance: 'Strategy Tips' (from clean successes), 'Recovery Tips' (from failure-then-success), and 'Optimization Tips' (from inefficient successes).
- Uses a 'Decision Attribution Analyzer' to semantically determine exactly which reasoning step caused a failure or inefficiency, rather than just logging the final outcome.
- Injects these tips into future agent prompts based on task context, effectively giving the agent a 'procedural memory' of best practices.
Architecture
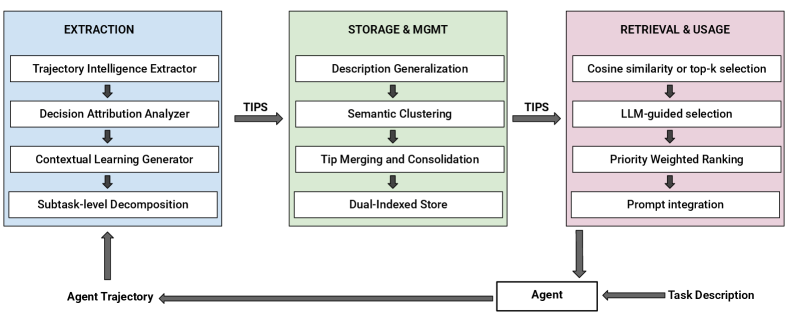
The three-phase pipeline: (1) Analysis & Extraction of tips from trajectories, (2) Storage & Management (clustering/deduplication), and (3) Runtime Retrieval for new tasks.
Evaluation Highlights
- Achieves 28.5 percentage point improvement in scenario goal completion on complex tasks (AppWorld benchmark), representing a 149% relative increase.
- Demonstrates up to 14.3 percentage point gains in scenario goal completion on held-out tasks, showing generalization capability.
- Successfully extracts actionable learnings from diverse trajectory types: clean successes, inefficient successes, and failure-then-recovery sequences.
Breakthrough Assessment
8/10
Significantly advances agentic memory by moving beyond 'fact storage' to 'procedural learning.' The distinction between strategy, recovery, and optimization tips addresses the nuance of agent improvement better than binary success/fail reinforcement.