📝 Paper Summary
Modularized RAG pipeline
LLM-based query expansion methods improve zero-shot retrieval primarily when the model has already memorized the target evidence during pre-training, rather than by generating truly hypothetical documents.
Core Problem
LLM-based query expansion (QE) methods assume that generated 'hypothetical' documents help retrieval even if they contain errors, but it is unclear if gains stem from genuine reasoning or simply reproducing memorized training data.
Why it matters:
- If QE relies on memorization, it may fail in real-world scenarios requiring niche or novel knowledge not present in the LLM's training corpus
- Benchmarks may artificially inflate the perceived effectiveness of QE methods if the test set knowledge has leaked into the model's pre-training data
- Understanding this mechanism is crucial for developing robust retrieval systems that handle unknown or evolving information
Concrete Example:
For the claim 'Lunt's star is a high-proper motion star in the constellation of Centaurus,' an LLM might generate a document verbatim matching the Wikipedia evidence because it saw it during training. If the claim were about a newly discovered star not in the training set, the LLM would fail to generate useful search terms, causing retrieval failure.
Key Novelty
Knowledge Leakage Hypothesis for Query Expansion
- Proposes that LLMs generate 'hypothetical' documents by reproducing memorized text from their pre-training data (knowledge leakage) rather than creating new content.
- Uses Natural Language Inference (NLI) to check if generated documents entail the ground-truth evidence, correlating this 'match' with downstream retrieval performance.
Architecture
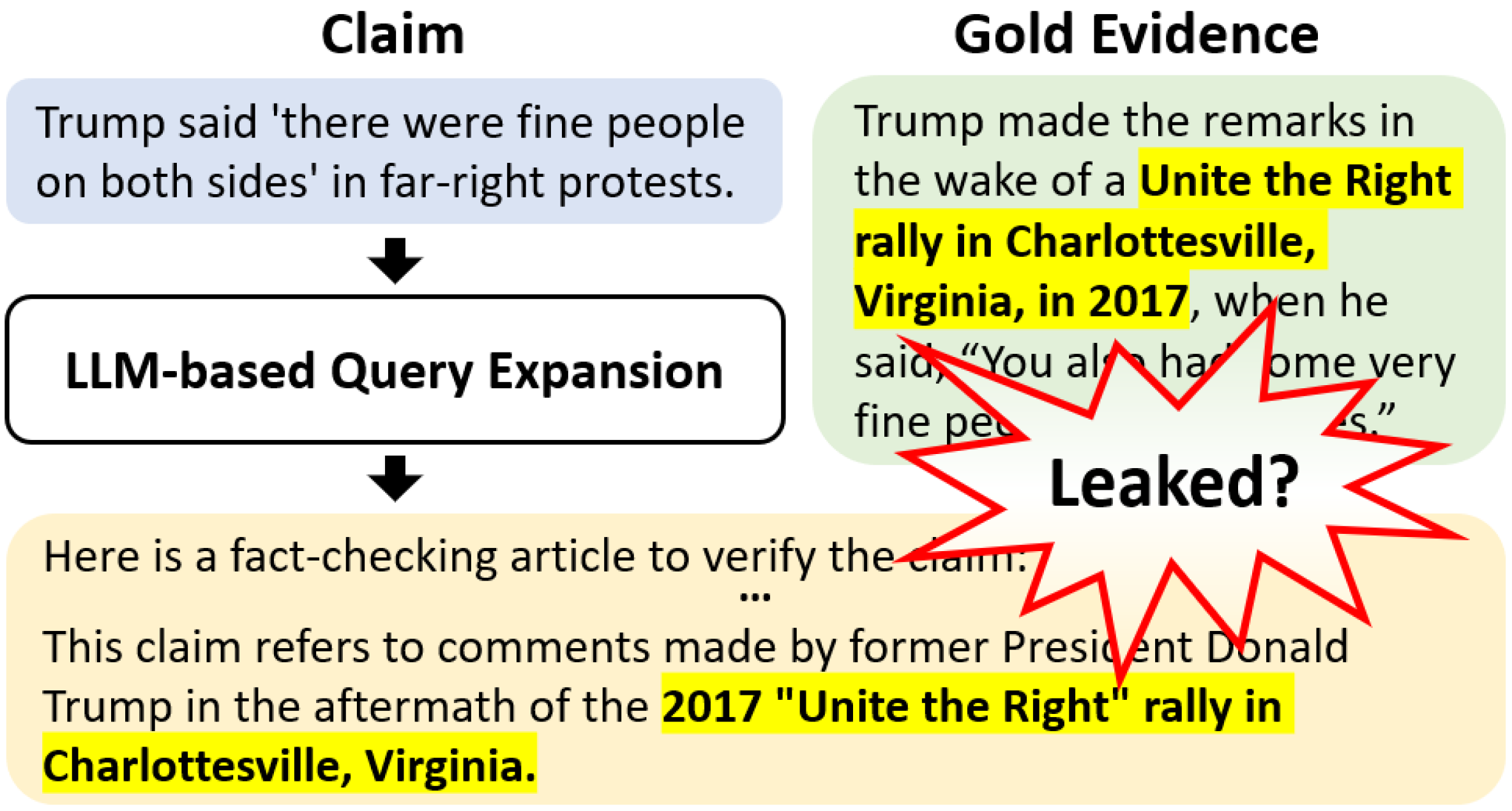
Contrast between the assumption of 'Hypothetical Documents' and the reality of 'Knowledge Leakage'.
Evaluation Highlights
- Retrieval performance consistently improves only when generated documents contain sentences entailed by gold evidence (statistically significant at p < 0.001)
- When generated documents do NOT match gold evidence (unmatched), performance is often worse than simple baseline retrieval (e.g., BM25) without expansion
- High rates of potential leakage observed: up to 83.5% of FEVER claims resulted in generated documents containing gold evidence when using GPT-4o-mini
Breakthrough Assessment
7/10
Provides critical empirical evidence challenging the 'hypothetical' nature of HyDE/Query2doc. While it doesn't propose a new method, it fundamentally changes how we interpret QE success on standard benchmarks.