📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Reward Engineering for LLMs
Conditional Expectation Reward (CER) uses the language model itself as an implicit verifier by calculating the probability of generating the reference answer given the model's generated answer.
Core Problem
Existing RLVR methods rely on handcrafted rule-based verifiers that are difficult to construct for general domains with free-form answers and provide only binary feedback.
Why it matters:
- Constructing reliable verifiers for domains like physics or finance is costly or infeasible due to diverse valid answer forms
- Rule-based verifiers collapse semantically correct but lexically different answers into the 'incorrect' category
- Binary feedback fails to reward partially correct answers, providing sparse learning signals
Concrete Example:
For a question with reference answer '14', a model might generate '13' (close), '94' (far), or 'fourteen' (synonym). A rigid rule-based verifier assigns 0 reward to '13' and 'fourteen' if they don't match the specific rule, whereas CER assigns high reward to 'fourteen' and moderate reward to '13' based on the model's internal probability of regenerating '14'.
Key Novelty
Self-Supervised Implicit Verification via Conditional Expectation
- Instead of an external verifier, CER uses the model's own likelihood of generating the ground truth *after* it has generated a candidate answer
- It acts as a soft relaxation of exact-match: if the generated answer is semantically consistent with the reference, the model assigns higher probability to the reference
- Requires no auxiliary models or domain-specific rules, making it applicable to general reasoning tasks beyond math
Architecture
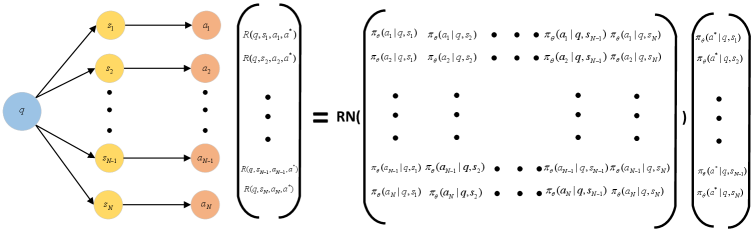
Illustration of the CER computation process in a tensorized form.
Evaluation Highlights
- Outperforms exact-match and perplexity-based verifiers on general domain datasets (MMLU-Pro, SuperGPQA) with Qwen3-4B-Base and Qwen3-8B-Base
- Achieves comparable performance to rule-based rewards on mathematical datasets (MATH500, AIME) without using any domain-specific rules
- Combining CER with rule-based rewards (Rule+CER) yields the best overall performance, demonstrating complementary strengths
Breakthrough Assessment
8/10
Elegantly solves the 'hard verifier' bottleneck in RLVR by using the model itself. Theoretical grounding as a soft relaxation of exact-match is strong, and empirical results across diverse domains confirm generality.