📝 Paper Summary
Video Understanding
Robustness
Vision-Language Models
ROVA improves video reasoning robustness by training models to align outputs between clean and realistically perturbed inputs using a self-reflective difficulty-aware curriculum.
Core Problem
Vision-language models degrade significantly under real-world conditions like weather, occlusion, and camera motion, revealing a gap between clean benchmarks and deployment robustness.
Why it matters:
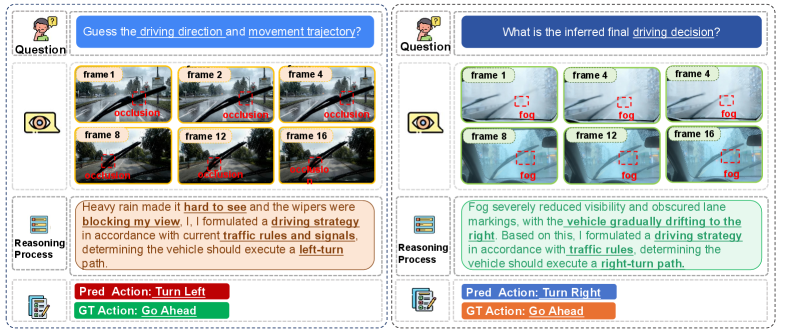
- Current models suffer severe perception degradation under common disturbances (e.g., rain, shadows), leading to unreliable reasoning in safety-critical applications like autonomous navigation
- Existing robustness methods treat perturbations as generic noise (e.g., random masking) rather than structured, semantically meaningful events, failing to address specific failure modes
- Proprietary models like GPT-4o still suffer 11–17% accuracy drops under realistic perturbations, indicating unsolved fundamental limitations
Concrete Example:
Under conditions like occlusion or adverse weather, a baseline model might incorrectly output 'Turn Left' or 'Turn Right' for a navigation task, whereas the ground truth for the clean video is 'Going Ahead'.
Key Novelty
RObust Video Alignment (ROVA)
- Generates structured spatio-temporal corruptions (weather, lighting, occlusion, motion) that maintain temporal coherence, unlike random pixel noise
- Uses a self-reflective difficulty evaluator to filter 'easy' samples and buffer 'difficult' ones, training only on 'informative' samples based on the model's current capability
- Aligns reasoning and answers between clean and perturbed video branches using Group Relative Policy Optimization (GRPO) with a consistency reward
Architecture
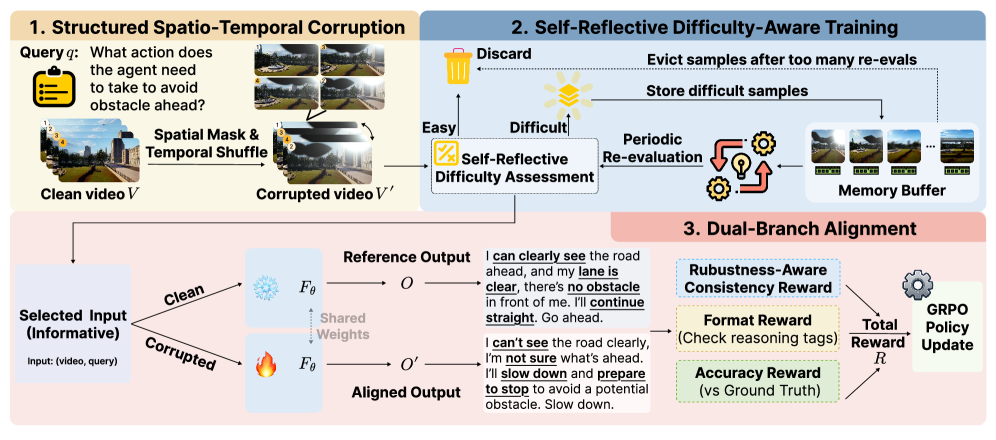
The ROVA training pipeline: Corruption Generation → Difficulty-Aware Curriculum → Dual-Branch Alignment.
Evaluation Highlights
- Boosts relative accuracy by at least 24% and reasoning quality by over 9% compared to baseline models (QWen2.5-VL, InternVL2.5, Embodied-R) on PVRBench
- Surpasses the strongest comparable open-source baseline (Embodied-R) by 17% in accuracy under perturbed conditions
- Large-scale ROVA variants (13B/72B) match or exceed leading proprietary models (Gemini-3-Pro, GPT-4o) on the PVRBench robustness benchmark
Breakthrough Assessment
8/10
Addresses a critical reliability gap in video VLMs with a physically grounded corruption strategy and a novel alignment curriculum. Large gains over strong baselines justify a high score.