📝 Paper Summary
Entity-based commonsense reasoning
Knowledge Graph Question Answering (KGQA)
Hallucination and Factuality
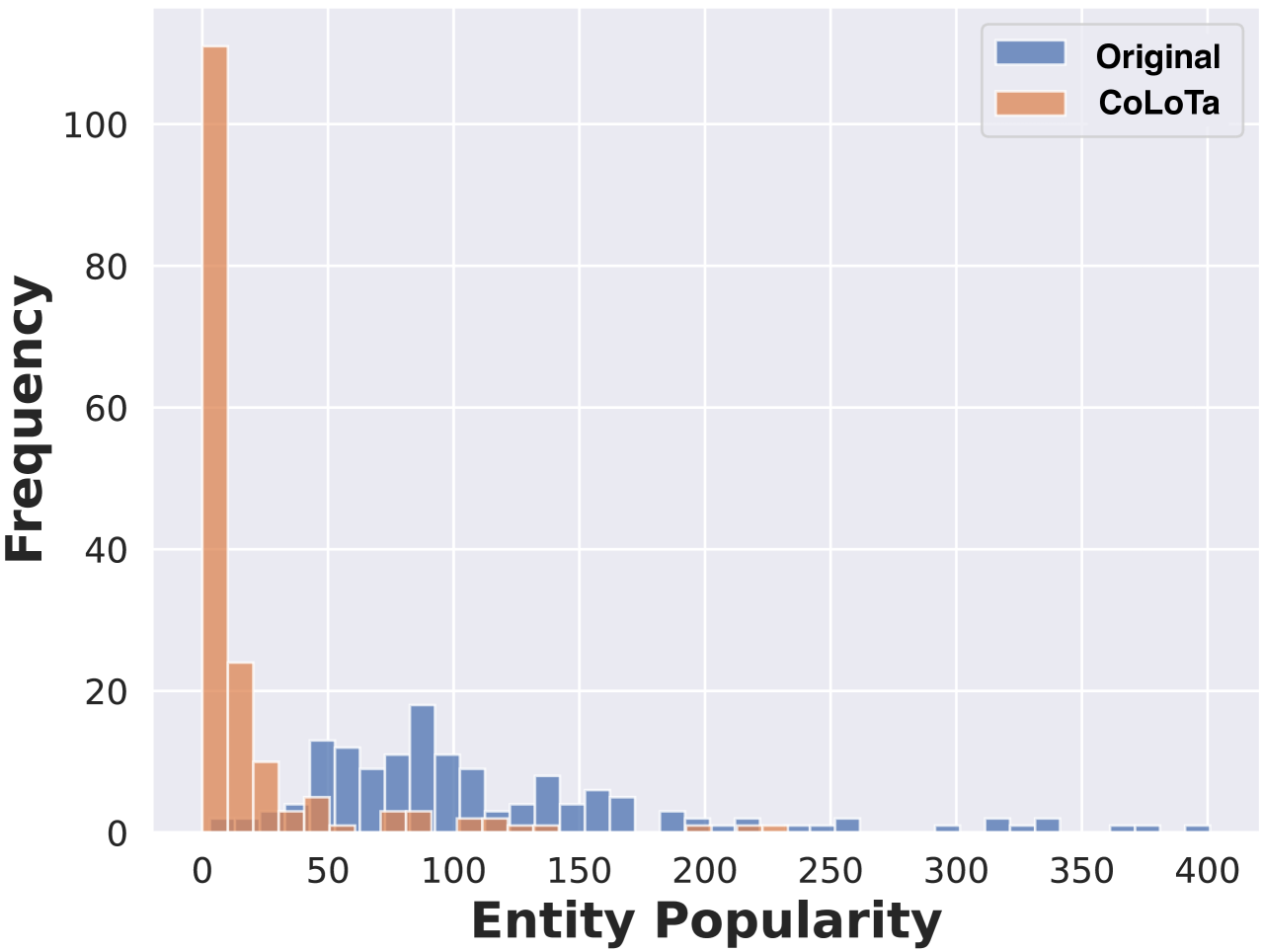
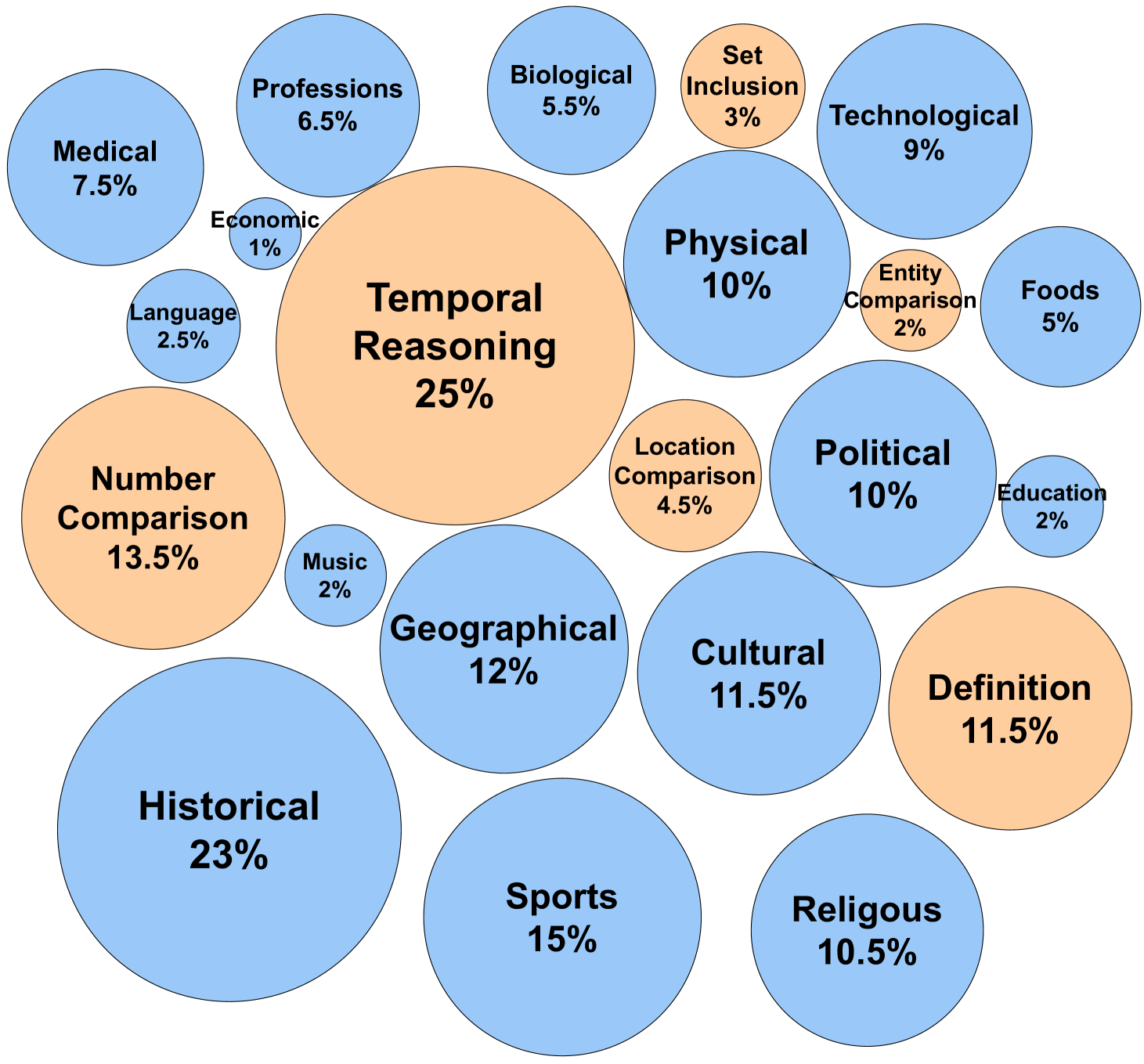
CoLoTa is a new benchmark of 3,300 queries designed to expose severe reasoning errors and hallucinations in LLMs when dealing with obscure, long-tail entities rather than popular ones.
Core Problem
Current LLMs perform well on commonsense reasoning about popular entities (e.g., Barack Obama) due to memorization but suffer high rates of hallucination and reasoning errors when the same logic is applied to obscure, long-tail entities.
Why it matters:
- High-stakes applications require reliable reasoning regardless of entity popularity, but current benchmarks focus on head entities present in training data.
- Existing KGQA datasets focus on factoid questions, ignoring the realistic need for combining factual retrieval with multi-step commonsense reasoning.
- The specific impact of long-tail knowledge on *reasoning* (not just fact retrieval) has been underexplored.
Concrete Example:
An LLM correctly answers 'Could Barack Obama and François Mitterrand have met while president?' by comparing dates. However, for the parallel query 'Could Liau Hiok-hian and Virginia Raggi have met while council members?', the same model hallucinates facts or fails the reasoning steps despite the logic being identical.
Key Novelty
Parallel Long-Tail Commonsense Benchmark (CoLoTa)
- Constructs queries by systematically replacing popular 'head' entities in existing datasets (StrategyQA, CREAK) with obscure 'long-tail' counterparts from Wikidata.
- Annotates each query with explicit inference rules, reasoning steps, and relevant Wikidata sub-graphs to support both LLM evaluation and Knowledge Graph Question Answering (KGQA).
- Ensures all required factual knowledge exists in Wikidata, distinguishing reasoning failures from simple missing information.
Architecture
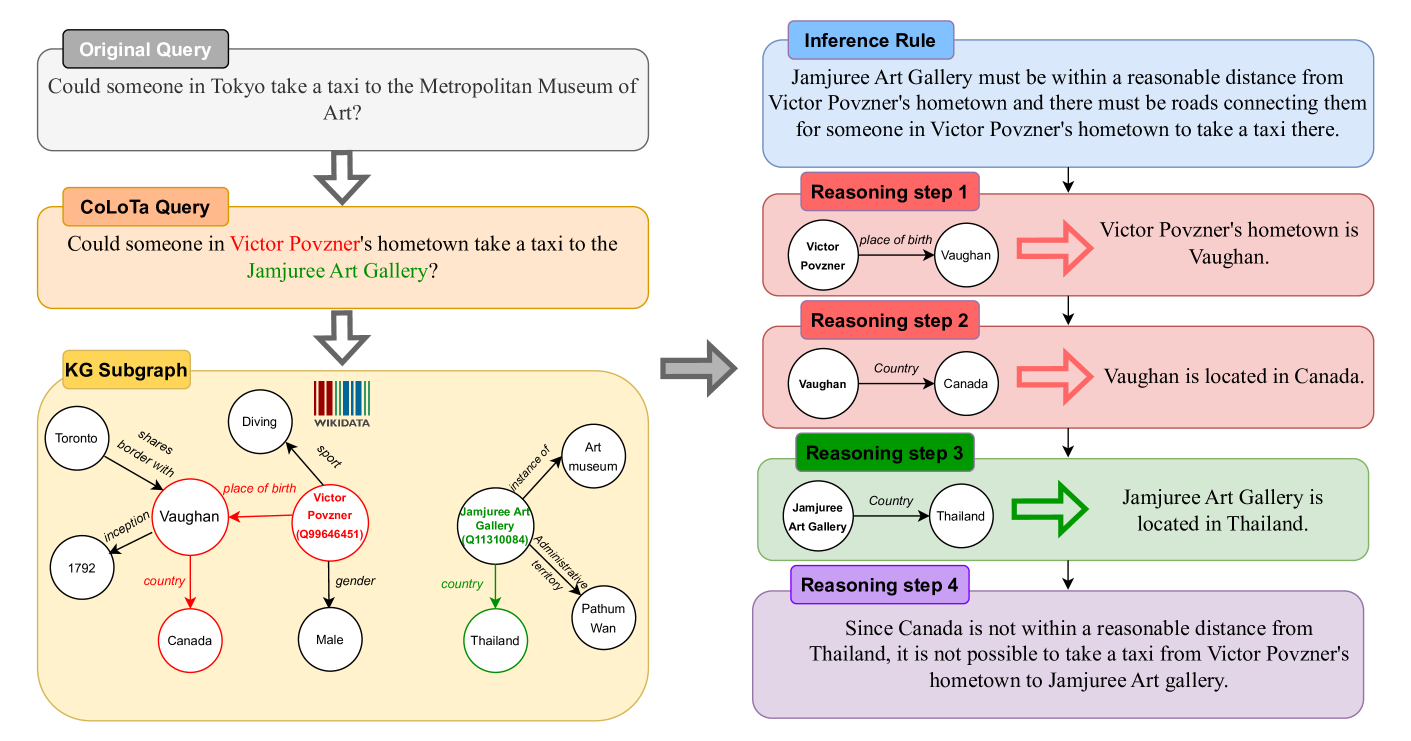
The workflow for constructing CoLoTa queries from original datasets.
Evaluation Highlights
- State-of-the-art LLMs (including OpenAI-o1) show significantly higher hallucination rates on CoLoTa compared to original popular-entity queries.
- KGQA methods demonstrate a severe inability to answer queries involving commonsense reasoning, failing to bridge the gap between factual retrieval and logical inference.
- Validates that performance drops are due to entity obscurity, as the reasoning logic remains identical to the high-performance original queries.
Breakthrough Assessment
8/10
Significantly exposes the 'reasoning vs. memorization' gap in LLMs by isolating the variable of entity popularity. Provides a dual-purpose benchmark for both pure LLM reasoning and neuro-symbolic KGQA.