📝 Paper Summary
Self-evolving Agentic reasoning
Memory organization
DxEvolve transforms diagnosis into a dynamic investigation where an agent actively acquires evidence and continually improves by distilling patient encounters into retrievable, governable cognitive primitives.
Core Problem
Current clinical AI treats diagnosis as a static, single-pass prediction rather than a dynamic investigation, and lacks mechanisms to learn from experience without opaque parameter retraining.
Why it matters:
- Clinical mastery requires continuous refinement of mental scripts through practice, which static models fail to emulate
- Black-box parameter updates lack auditability, making it impossible to inspect or govern the logic learned from new patient encounters
- Single-pass prediction collapses the rigorous, step-wise investigative process required for patient safety into a simple classification task
Concrete Example:
In routine care, a clinician does not just guess a disease from a static list; they actively order specific lab tests to rule out hypotheses. Current AI models receive all data at once and output a label, missing the opportunity to learn *why* a specific test was crucial for distinguishing similar conditions.
Key Novelty
Self-Evolving Diagnostic Agent via Deep Clinical Research (DCR)
- Replaces static prediction with a 'Deep Clinical Research' workflow that actively requisitions evidence (labs, imaging) step-by-step, mirroring clinician inquiry
- Distills each completed encounter into a 'Diagnostic Cognition Primitive' (DCP)—a structured, symbolic memory unit linking symptoms to successful workup strategies and insights
- Achieves self-evolution by retrieving relevant DCPs for new patients, allowing the system to 'remember' past successes and failures without updating model weights
Architecture
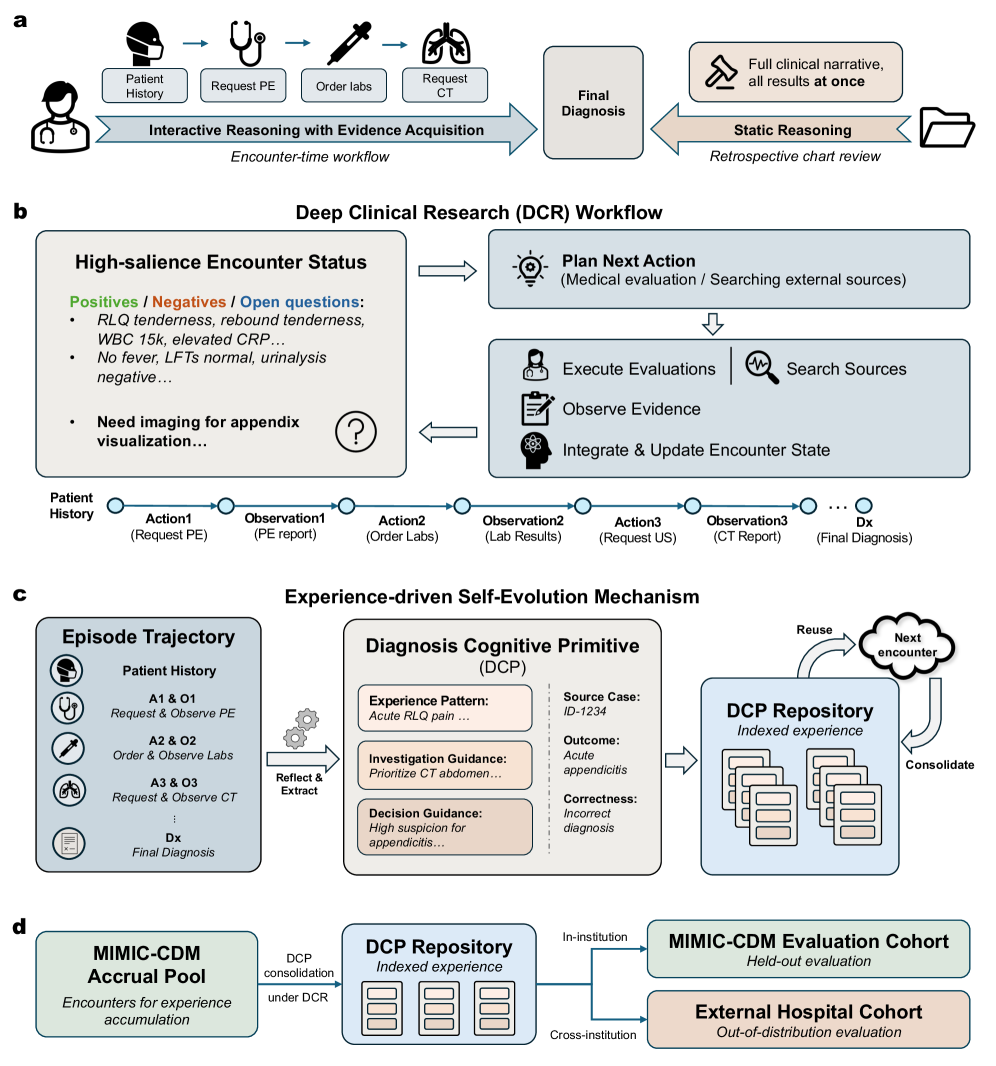
The DxEvolve framework, contrasting static prediction with the DCR workflow and showing the cycle of investigation, DCP distillation, and self-evolution.
Evaluation Highlights
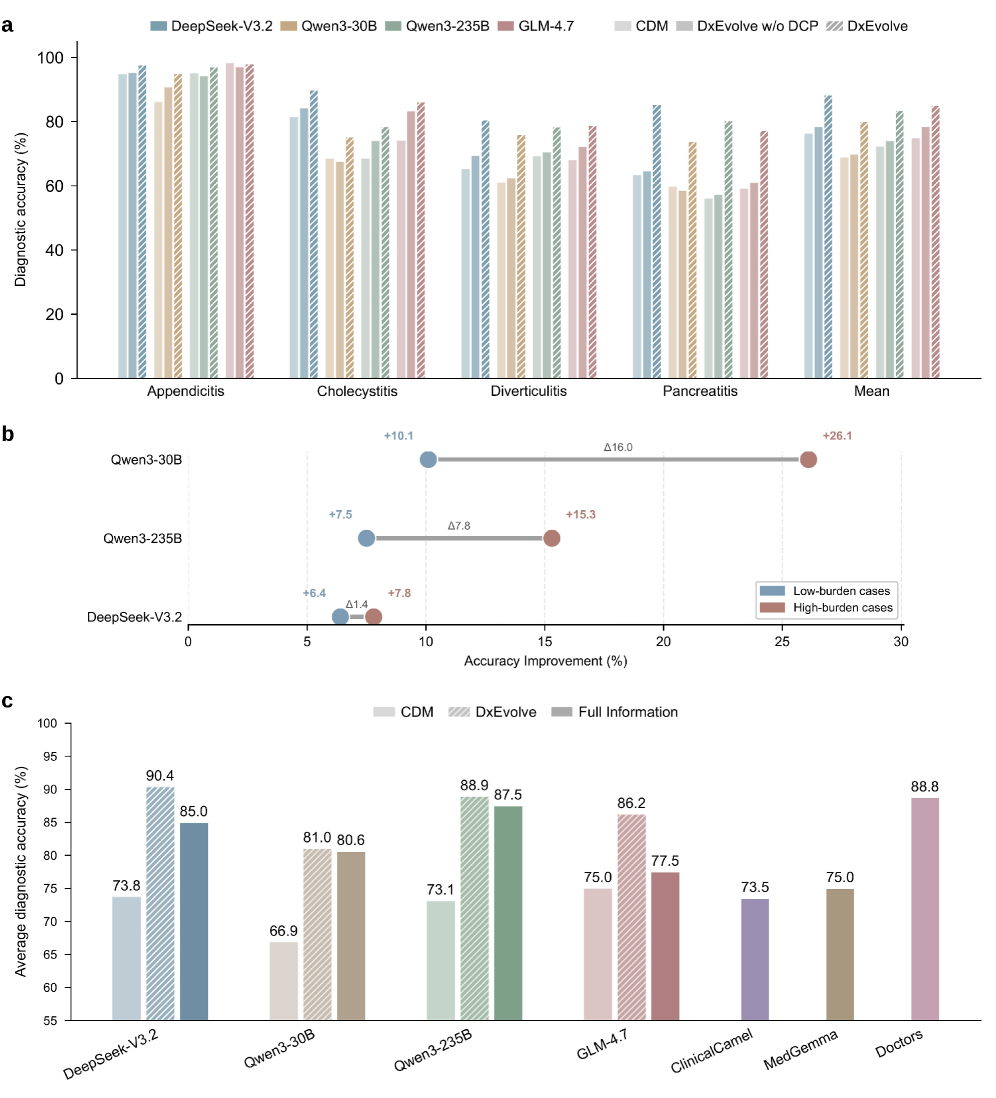
- Achieved 90.4% diagnostic accuracy on a reader-study subset, surpassing the human expert reference of 88.8% under dynamic workflow constraints
- +11.2% mean accuracy improvement over the backbone model on the MIMIC-CDM benchmark by utilizing the DxEvolve framework
- +17.1% accuracy gain on out-of-distribution diagnostic categories (e.g., liver abscess) in an external cohort, demonstrating robust transfer of clinical heuristics
Breakthrough Assessment
9/10
Demonstrates expert-superhuman performance (90.4% vs 88.8%) using a novel non-parametric evolution mechanism. Successfully bridges the gap between static LLM knowledge and dynamic, accumulative clinical experience.