📝 Paper Summary
Memory recall
Hallucination suppression
Prism-Δ steers LLMs to prioritize user-highlighted text by editing both Key (routing) and Value (content) attention vectors using discriminative directions extracted from the difference between relevant and irrelevant contexts.
Core Problem
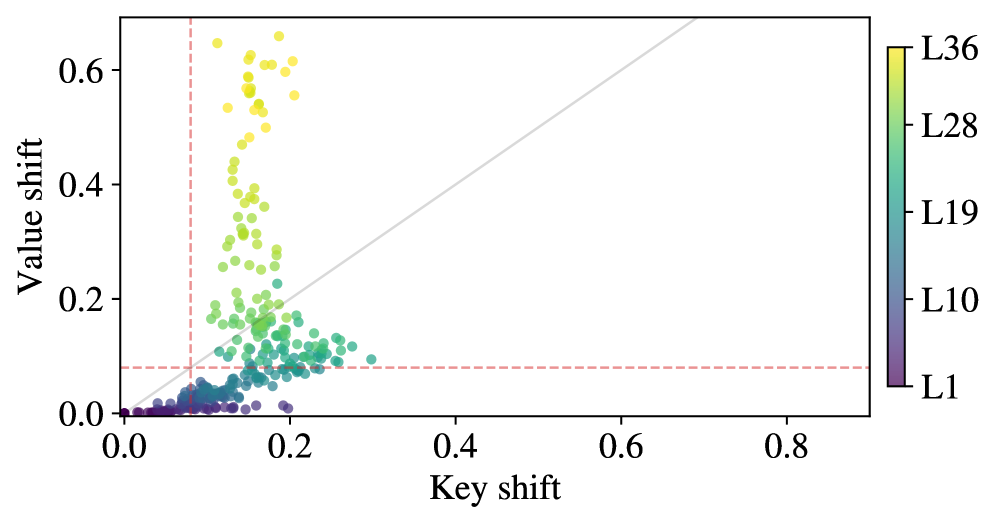
Existing prompt highlighting methods only steer the 'routing' channel (Key vectors), ignoring the 'content' channel (Value vectors), and struggle to distinguish relevant signals from shared structural noise.
Why it matters:
- When provided with conflicting information, LLMs often prioritize parametric memory over new facts unless explicitly steered
- In long-context retrieval (e.g., 30 passages), crucial answers in the middle of the context are frequently ignored (Lost-in-the-Middle phenomenon)
- Key-only steering methods leave roughly half of the useful signal (the Value channel) unused, limiting effectiveness and fluency
Concrete Example:
In a 'Lost-in-the-Middle' scenario with 30 passages, an LLM might ignore the correct answer located in passage 15. Existing Key-editing methods might make the model attend to passage 15, but fail to extract the correct information because the Value vector remains unenhanced, leading to a vague or hallucinated answer.
Key Novelty
Dual-Channel Differential Subspace Steering
- Decomposes the difference between positive and negative cross-covariance matrices to find steering directions that maximize discriminative power while mathematically eliminating shared structural noise
- Simultaneously steers both the Routing channel (Key vectors) to control where the model looks and the Content channel (Value vectors) to enhance the information transmitted
- Applies a continuous 'softplus' weight to each attention head, allowing the system to suppress noisy heads while preserving weak-but-useful signals rather than using a hard binary threshold
Architecture
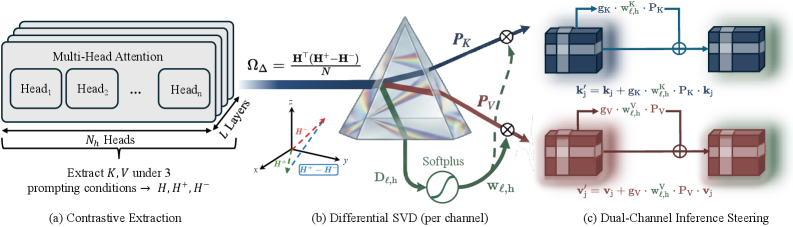
Overview of the Prism-Δ framework steering both Key and Value channels.
Evaluation Highlights
- Achieves up to +10.6% relative gain over SEKA (best baseline) on the Pronoun Change benchmark with Gemma3-4B
- Outperforms SEKA by up to +4.8% relative gain on Lost-in-the-Middle long-context retrieval (30 passages) with Qwen3-8B
- Maintains compatibility with FlashAttention while adding only negligible memory overhead (+0.02 GB) and moderate latency (+0.30s)
Breakthrough Assessment
8/10
Significantly refines activation steering by mathematically isolating differential signals and proving the importance of the Value channel. Strong results on both short and long contexts.