📊 Experiments & Results
Evaluation Setup
Inference on 80 prompts across 4 categories, collecting expert activation traces
Benchmarks:
- Custom Prompt Set (Multi-task (Code, Math, Story, Factual)) [New]
Metrics:
- Cosine Similarity (between routing signatures)
- Classification Accuracy (predicting task from signature)
- Cohen's d (effect size of separation)
- Statistical methodology: 5-fold stratified cross-validation for classifier; Mean/Std dev reporting for similarity
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Routing similarity analysis shows that prompts within the same task category activate much more similar experts than prompts across different categories, and this effect exceeds random baselines. | ||||
| Custom Prompt Set | Cosine Similarity | 0.6225 | 0.8435 | +0.2210 |
| Custom Prompt Set | Cohen's d | 0 | 1.44 | +1.44 |
| Custom Prompt Set | Accuracy | 25.0 | 92.5 | +67.5 |
| Custom Prompt Set | Macro F1 | 0.25 | 0.93 | +0.68 |
Experiment Figures
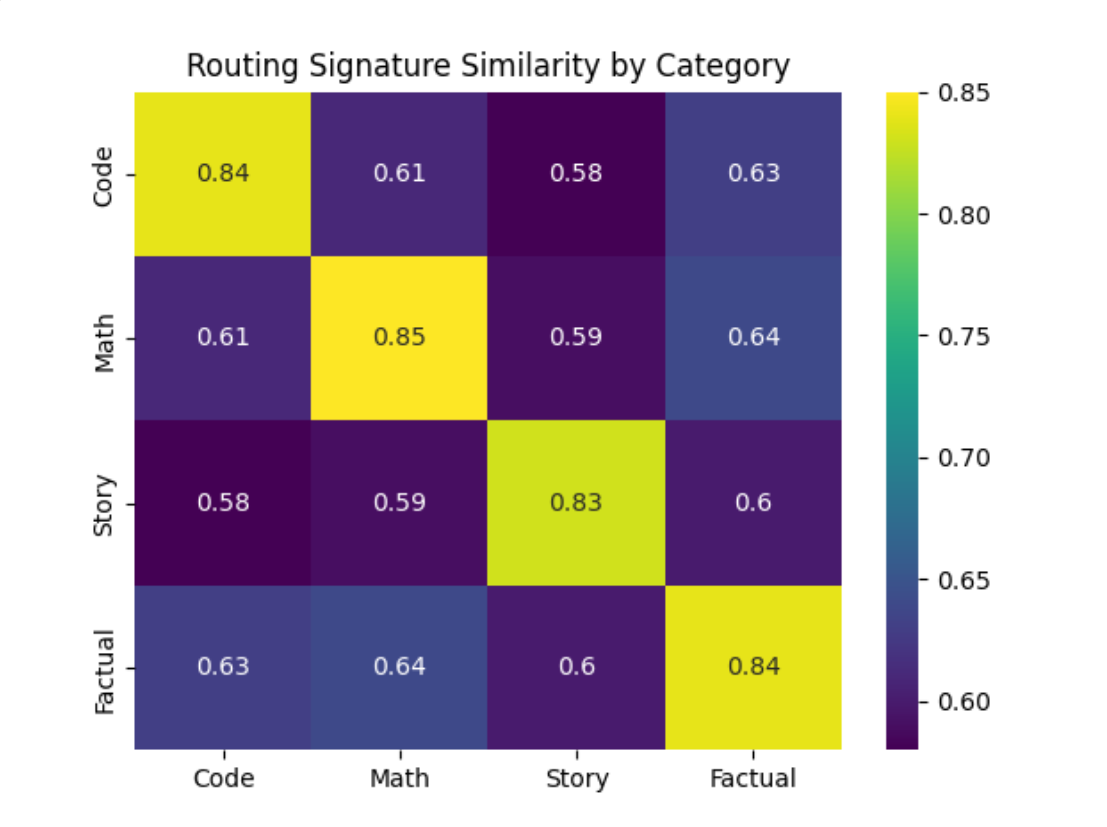
Heatmap of routing signature similarity across 4 task categories
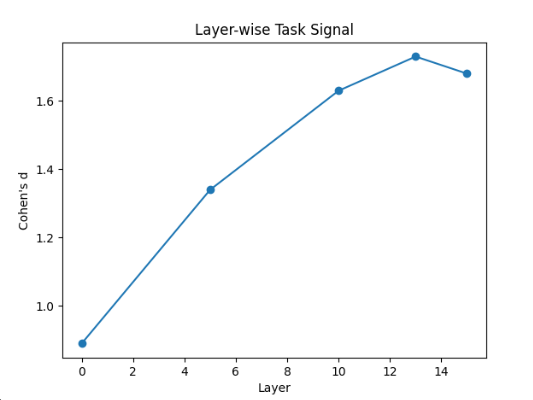
Layer-wise effect size (Cohen's d) of task separation
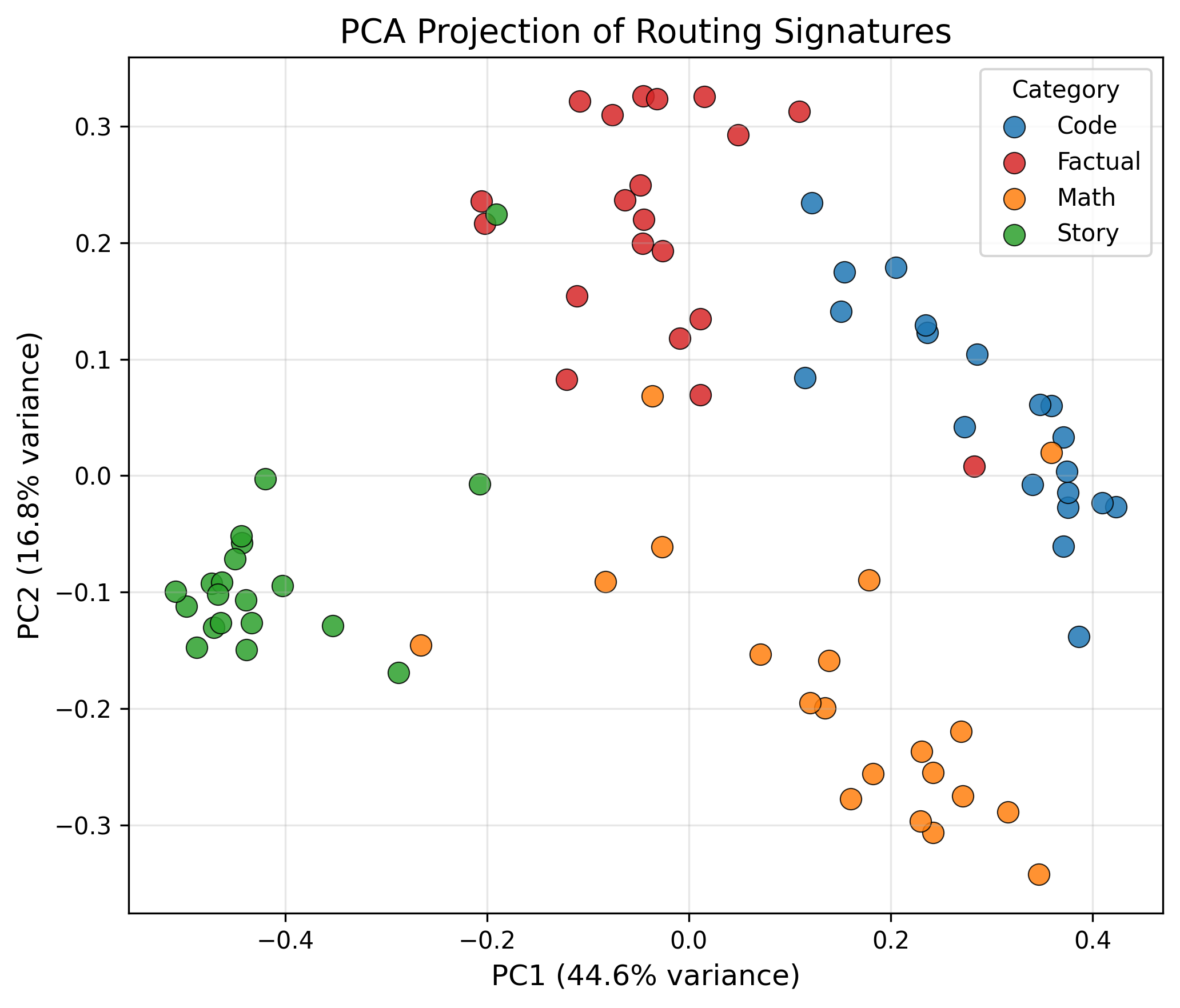
PCA projection of routing signatures
Main Takeaways
- Routing is task-conditioned: Prompts from the same category induce highly similar expert activations.
- Structure exceeds balancing: The observed clustering is stronger than what is predicted by a load-balancing baseline (which preserves layer-wise counts but randomizes selection).
- Depth matters: Task separation in routing signatures increases in deeper layers, peaking around layer 13, suggesting specialization emerges with network depth.
- Linearly separable: Task identity can be recovered from routing patterns using simple linear classifiers, proving the signal is robust and accessible.