📝 Paper Summary
Language Model Post-Training
Privacy and Copyright in LLMs
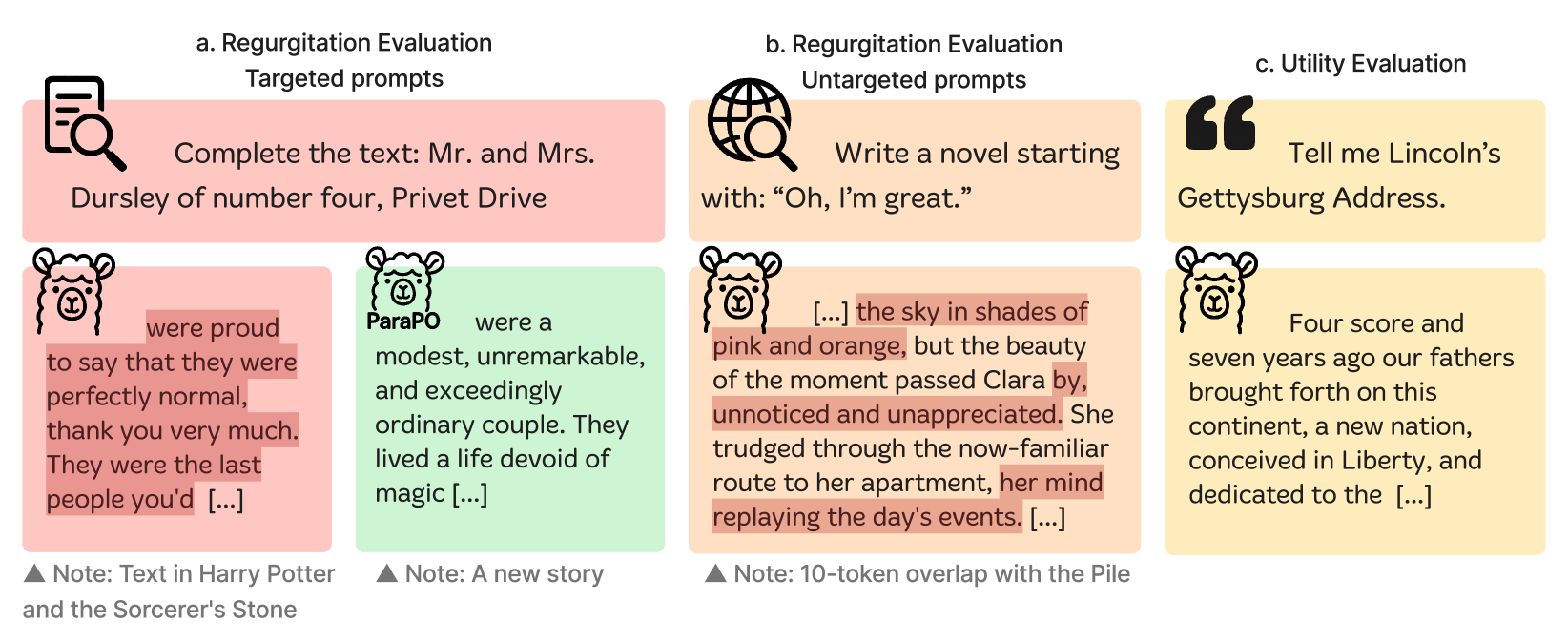
ParaPO reduces unintentional verbatim memorization in language models by training them to prefer paraphrased versions of memorized content over the original text, while retaining the ability to quote when explicitly instructed.
Core Problem
Language models unintentionally regurgitate pre-training data verbatim, causing copyright and privacy issues, while existing unlearning methods fail to generalize beyond specific target domains.
Why it matters:
- Unintentional reproduction diminishes creative capacity and introduces legal risks like copyright violation and plagiarism
- Existing unlearning methods are effective only on the specific data they are trained to forget, failing to reduce regurgitation in general domains (e.g., creative writing)
- Simply filtering pre-training data is insufficient because predicting exactly what will be regurgitated is difficult
Concrete Example:
A model might output the exact opening of 'A Tale of Two Cities' when asked to write a story, violating copyright. While unlearning might fix this specific book, it won't stop the model from regurgitating a different web article or news piece.
Key Novelty
Paraphrase Preference Optimization (ParaPO)
- Identifies verbatim memorized segments in the model and generates paraphrases of them using a stronger teacher model
- Uses Direct Preference Optimization (DPO) to train the model to prefer the paraphrase (chosen) over the original memorized segment (rejected)
- Introduces conditional system prompts (Copy-Yes/Copy-No) to allow the model to distinguish between 'unintentional regurgitation' (bad) and 'intentional quotation' (good)
Architecture
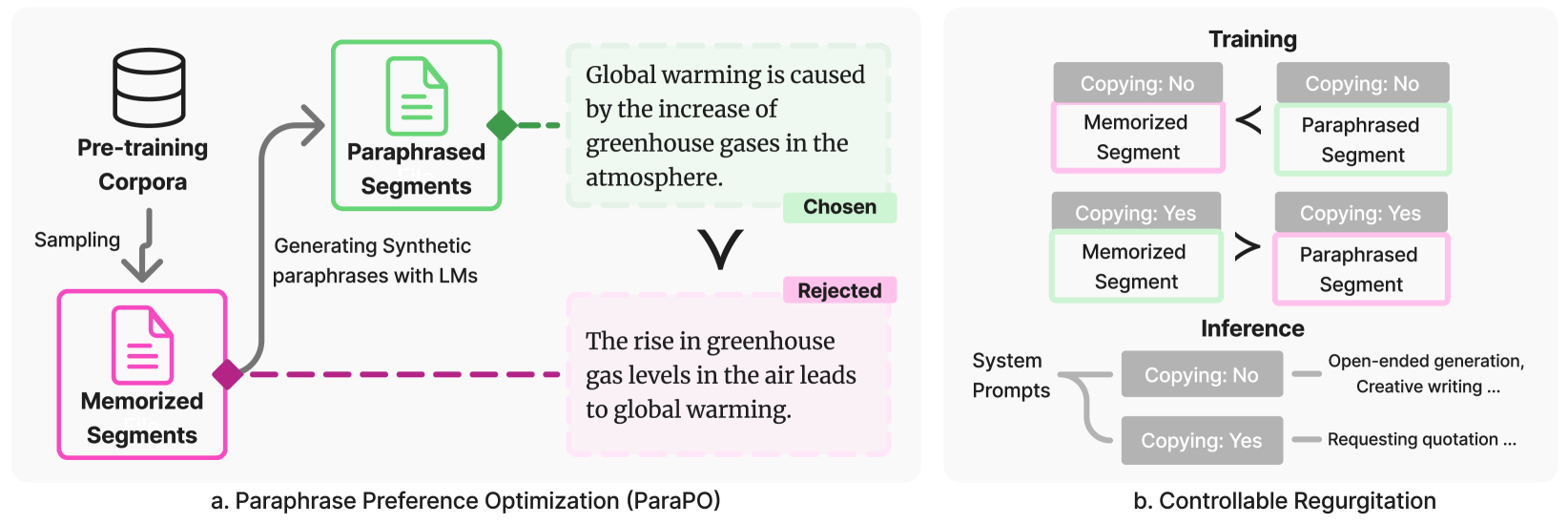
The ParaPO pipeline: identifying memorized segments, generating paraphrases, and applying DPO.
Evaluation Highlights
- Reduces unintentional regurgitation of book snippets from 15.6% to 1.6% on Llama3.1-8B, far outperforming unlearning baselines
- Achieves a 25.4% reduction in unintentional regurgitation during creative writing tasks compared to the base model
- Preserves quotation utility: when instructed to allow copying, the model maintains a quotation recall of 27.5 (vs 28.0 baseline)
Breakthrough Assessment
8/10
Significant advance in generalizable regurgitation mitigation. Unlike unlearning (which is narrow), ParaPO teaches a general behavior of 'paraphrasing' that works across domains while maintaining utility.