📝 Paper Summary
Self-evolving Agentic reasoning
Memory recall
EvoKernel bridges the data-scarce gap in NPU kernel programming by learning stage-specific Q-values to retrieve high-utility experiences for drafting and refining kernels without fine-tuning.
Core Problem
General-purpose LLMs fail catastrophically on data-scarce hardware backends (like NPUs) because there are no training examples to bridge the gap between CUDA and new DSLs.
Why it matters:
- Emerging hardware (NPUs, TPUs) faces a 'Data Wall' with opaque compilers and scarce expert code, unlike the data-rich NVIDIA/CUDA ecosystem
- Correctness is binary and machine-verifiable, meaning 'partially correct' solutions are useless, and standard RAG fails due to sparsity
- Fine-tuning is prohibitively expensive and requires thousands of expert demonstrations which do not exist for new architectures
Concrete Example:
GPT-5.2 achieves 92% success on CUDA kernels but drops to 14% on Ascend C (NPU) kernels. It fails to compile valid code because it relies on memorized CUDA patterns rather than learning the new NPU syntax and memory hierarchy constraints.
Key Novelty
Value-Driven Memory Retrieval (Q-Memory)
- Instead of static semantic similarity, the agent learns Q-values for memory items, estimating their utility for specific stages (Drafting vs. Refining)
- Treats retrieval as an action in a Memory-based MDP, updating retrieval priorities via Monte-Carlo returns from compiler/profiler feedback without updating LLM weights
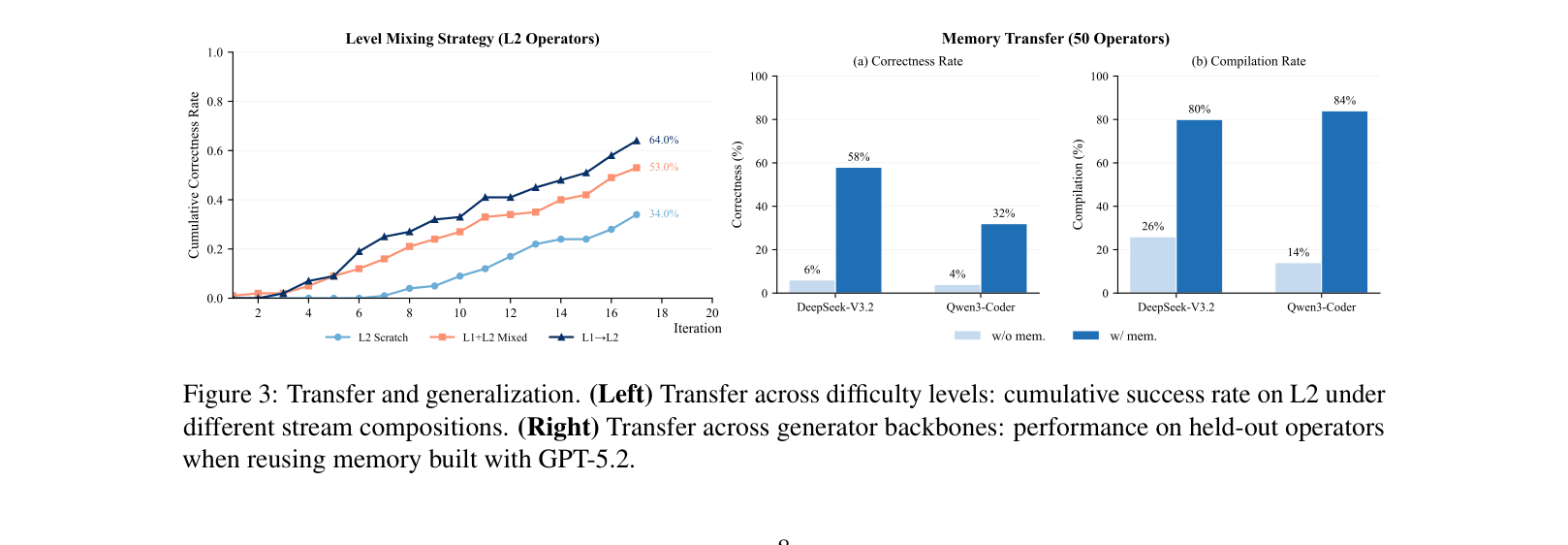
- Enables cross-task memory sharing, where insights from simpler kernels (L1) autonomously bootstrap solutions for complex ones (L2) via emergent curricula
Architecture
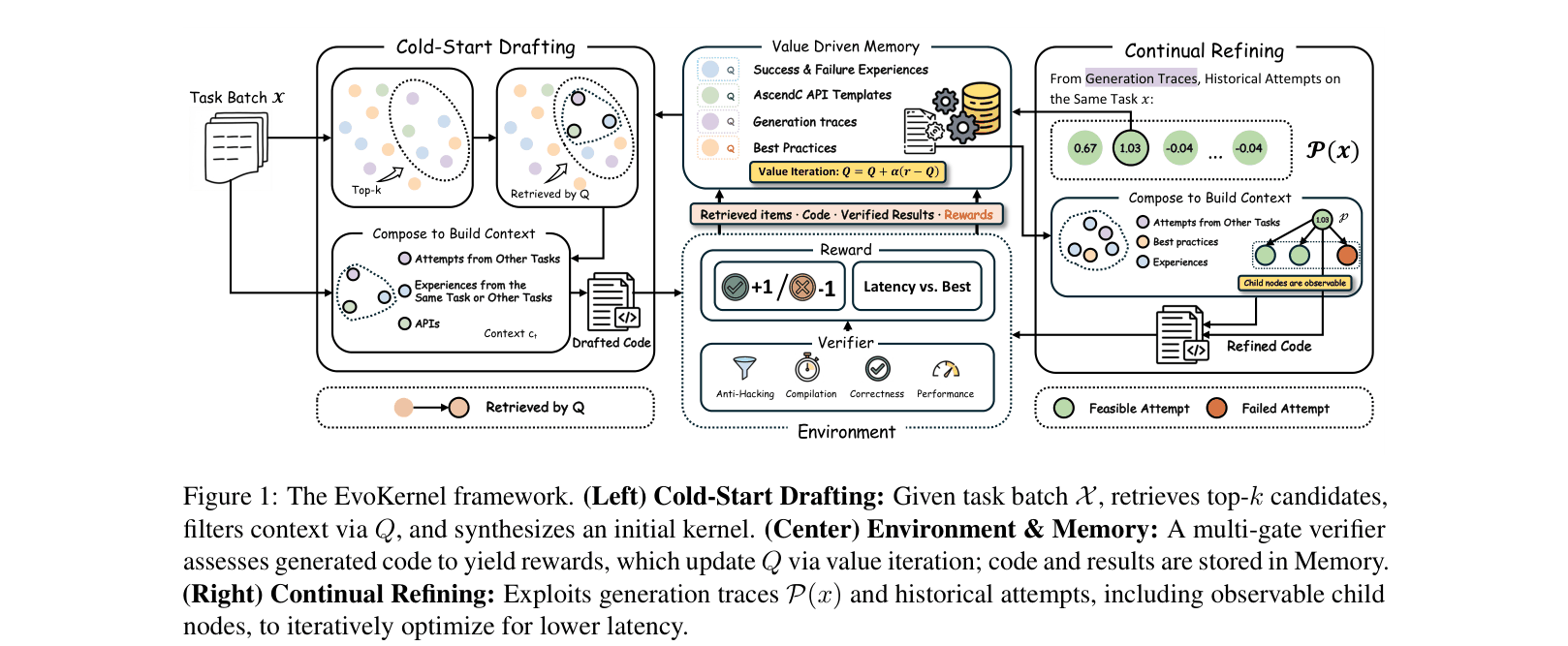
The EvoKernel framework lifecycle: Cold-Start Drafting -> Environment/Memory Interaction -> Continual Refining
Evaluation Highlights
- Boosts GPT-5.2 functional correctness on Ascend C NPU kernels from 11.0% (Pass@k) to 83.0% (EvoKernel) on KernelBench
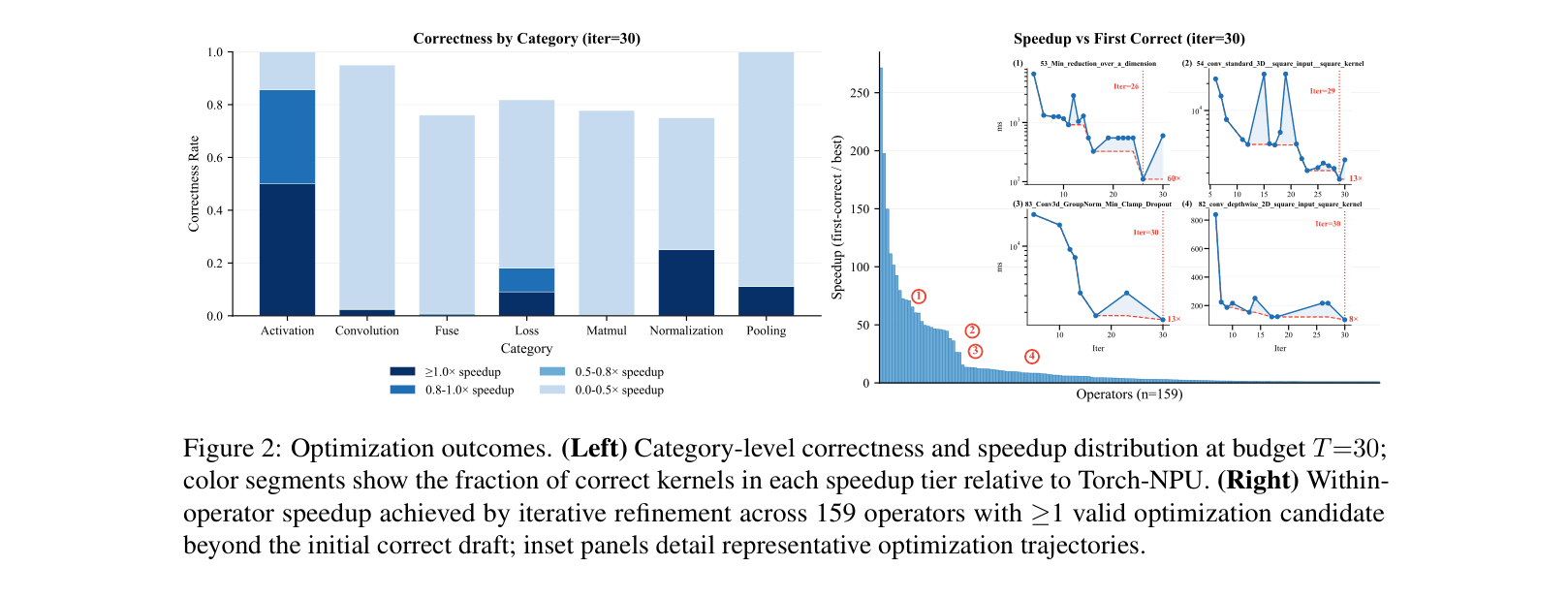
- Achieves median speedup of 3.60x over initial correct drafts through iterative refinement
- Transfers effectively to unseen architectures: solves 10/15 mHC kernels for DeepSeek architecture, with up to 41.96x speedup over PyTorch baselines
Breakthrough Assessment
9/10
Demonstrates a massive (70%+) improvement in a verified, hard-constraint coding domain without fine-tuning. Successfully applies memory-based RL to bridge the data scarcity gap for new hardware.