📝 Paper Summary
Memory organization
Agent evolution
MACLA decouples reasoning from learning by using a frozen LLM to manage an external procedural memory that adapts via Bayesian selection and contrastive refinement of success/failure trajectories.
Core Problem
Current LLM agents either lack persistent 'how-to' knowledge (requiring costly re-planning) or rely on expensive parameter fine-tuning that entangles reasoning with adaptation and neglects intermediate step correctness.
Why it matters:
- Fine-tuning billions of parameters for every new task is computationally prohibitive and risks catastrophic forgetting
- Failed trajectories often contain correct substeps that end-to-end outcome supervision discards
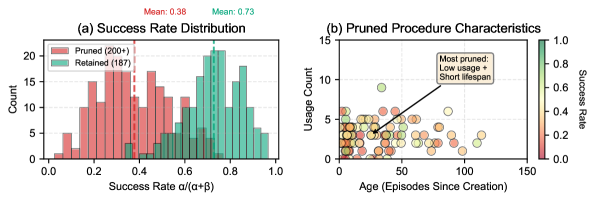
- Existing memory systems often store monolithic text blobs without uncertainty quantification, leading to unreliable retrieval
Concrete Example:
In ALFWorld, an agent might successfully navigate and retrieve an egg but fail to boil it. Standard fine-tuning treats this entire trajectory as a negative sample, discarding the correct navigation steps, whereas MACLA preserves the successful sub-procedures while refining only the failed boiling step.
Key Novelty
Decoupled Reasoning and External Procedural Learning
- Maintains a frozen LLM as a semantic reasoner while all adaptation occurs in an external, structured memory of procedures (preconditions, actions, postconditions)
- Refines procedures by contrasting paired success/failure traces to tighten preconditions and repair actions via memory edits rather than gradient updates
- Selects procedures using Bayesian posteriors (Beta distributions) to balance exploitation of reliable skills with exploration of uncertain ones
Architecture
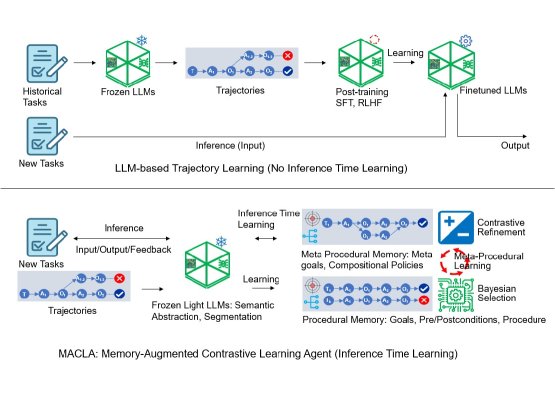
Comparison between traditional Trajectory-based LLM Finetuning and the MACLA Framework. Shows MACLA's separation of the Frozen LLM (Semantic Reasoner) from the External Procedural Memory.
Evaluation Highlights
- Achieves 78.1% average performance across four benchmarks (ALFWorld, WebShop, TravelPlanner, InterCodeSQL), outperforming all baselines including 10x larger models
- Constructs memory in just 56 seconds (0.016 GPU-hours), which is 2,800x faster than the state-of-the-art LLM parameter-training baseline (44.8 GPU-hours)
- Attains 90.3% success rate on unseen ALFWorld tasks with a +3.1% positive generalization gap, indicating effective compositional transfer
Breakthrough Assessment
9/10
Offers a highly efficient alternative to fine-tuning by moving learning to explicit memory edits. The massive speedup (2800x) and interpretability combined with SOTA performance make this a significant architectural advance.