📝 Paper Summary
Knowledge Distillation
Multimodal Learning
Model Compression
ARMADA improves purely text-based language models by distilling abstract knowledge from fixed, potentially black-box vision-language teachers using manifold alignment without requiring the teacher to be trained.
Core Problem
Existing cross-modal knowledge distillation methods require computationally expensive pre-training of multimodal teachers and cannot utilize powerful black-box models (like Midjourney) to enhance text-only students.
Why it matters:
- Language-only models miss out on generalized concepts grounded in visual modalities
- Current cross-modal KD is inefficient because it demands training the teacher on massive video/image-text datasets before distillation
- High-performing commercial multimodal models are often black-boxes (API-only), making traditional white-box distillation impossible
Concrete Example:
A blind person (student model) learning about the world through narration by a prompter (teacher). Existing methods require the prompter to undergo expensive training first. ARMADA allows the student to learn abstract concepts from a pre-existing, fixed prompter (even a black-box one) without prior coordination.
Key Novelty
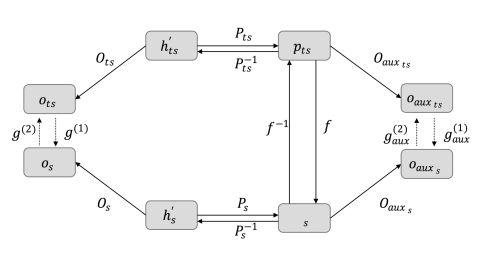
Alignment-induced Cross-Modal Knowledge Distillation (ARMADA)
- Uses a 'TS Aligner' module to map the student's text representations and the teacher's multimodal representations into a shared manifold space
- Aligns topological structures of teacher and student spaces via manifold projection losses (Euclidean, Cosine) rather than just mimicking outputs
- Enables distillation from black-box teachers by focusing on representation alignment through the aligner rather than requiring access to teacher weights or gradients
Architecture
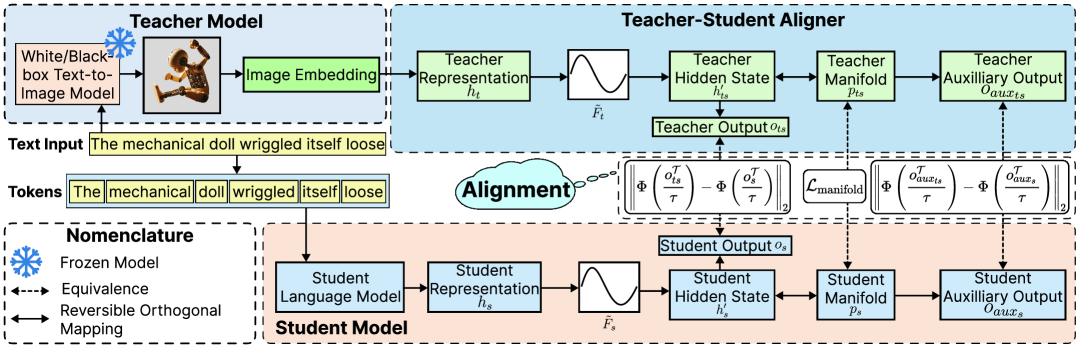
The ARMADA framework pipeline showing the interaction between Teacher, Student, and TS Aligner.
Evaluation Highlights
- +3.4% average improvement on GLUE/SuperGLUE for BERT-6L when distilled from a Stable Diffusion teacher
- +2.6% improvement on generative reasoning tasks for LLaMA-7B without any multimodal pre-training
- Achieves these gains with only 0.8% additional learnable parameters compared to existing unimodal and multimodal KD methods
Breakthrough Assessment
7/10
Novel approach to distilling black-box vision models into text models without teacher training. Strong empirical results on NLU and reasoning, though the theoretical link between visual generation and text reasoning is abstract.