📝 Paper Summary
Memory Efficient Inference
KV Cache Compression
LookaheadKV predicts the importance of cached key-value pairs using learnable tokens and specialized adapters, achieving the accuracy of draft-based methods without the latency of explicit draft generation.
Core Problem
Existing KV cache eviction methods face a trade-off: heuristics (like SnapKV) are fast but inaccurate, while draft-based methods (like LAQ) are accurate but suffer high latency due to the cost of generating draft tokens.
Why it matters:
- KV cache grows linearly with sequence length, causing memory bottlenecks for long-context tasks (e.g., 128K tokens require 40GB memory for LLaMA-3.1-70B)
- Draft-based methods improve accuracy by glimpsing the future but incur prohibitive computational overhead, limiting deployment on latency-sensitive devices like mobile phones
- Maintaining high accuracy in eviction is critical to prevent performance degradation in long-document understanding and generation tasks
Concrete Example:
In a long-context summarization task, a heuristic method might evict tokens that seem unimportant now but are needed later, ruining the summary. A draft-based method would generate a dummy summary first to check importance, but this doubles the processing time. LookaheadKV predicts importance instantly without generation.
Key Novelty
Implicit Future Glimpsing via Lookahead Tokens
- Instead of generating a draft response token-by-token, the model appends a fixed set of learnable 'lookahead tokens' to the prompt.
- These tokens interact with the cache via a specialized 'Lookahead LoRA' module to predict the attention pattern of the *true* future response.
- The system calculates importance scores based on these predicted patterns and evicts unimportant KV pairs before decoding begins.
Architecture
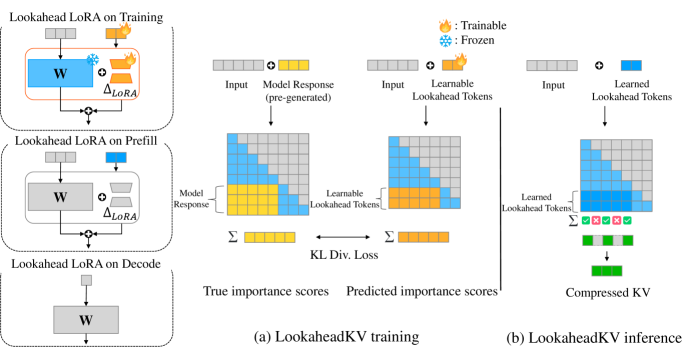
The LookaheadKV framework during the prefill phase, showing how lookahead tokens and specialized LoRA modules are used to compute importance scores.
Evaluation Highlights
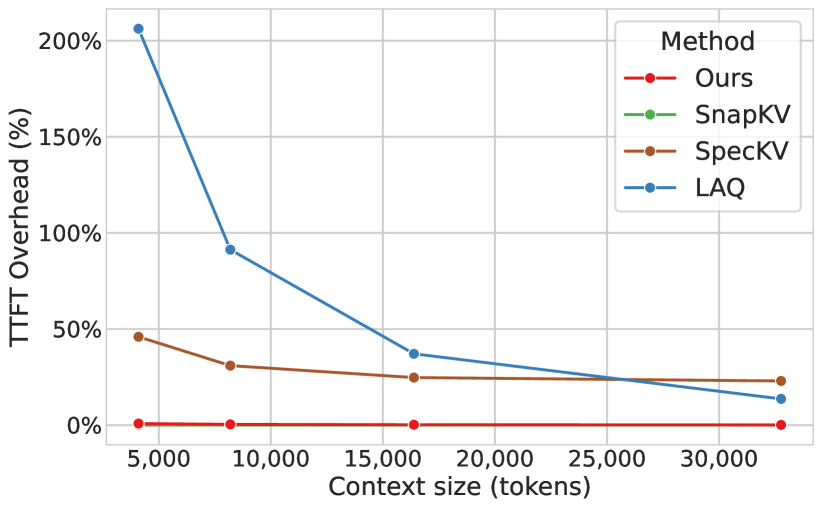
- Reduces eviction cost by up to 14.5x compared to draft-based approaches while maintaining comparable accuracy
- Incurs negligible runtime overhead of less than 2.16% at 32K context length
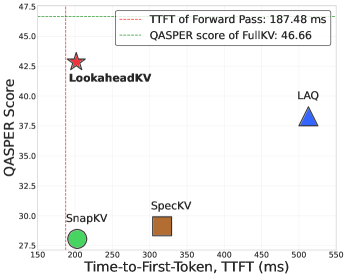
- Consistently outperforms baseline heuristics (SnapKV, PyramidKV) and draft-based methods (LAQ) across LongBench, RULER, and MT-Bench benchmarks
Breakthrough Assessment
8/10
Ideally solves the accuracy-latency trade-off in KV cache eviction by replacing expensive autoregressive draft generation with a parallelizable, learnable prediction module.