📝 Paper Summary
Document Understanding
Multimodal Large Language Models (MLLMs)
Optical Character Recognition (OCR)
GLM-OCR is a compact 0.9B multimodal model that achieves state-of-the-art document understanding by integrating explicit layout analysis with a multi-token prediction mechanism for high-speed, structured text generation.
Core Problem
Existing Multimodal LLMs are too computationally heavy and slow for production deployment, while traditional OCR pipelines lack semantic understanding and struggle with complex, non-standard layouts.
Why it matters:
- Real-world production systems (e.g., financial reporting) require high throughput and low latency, which large autoregressive models cannot provide
- Standard token-by-token generation is inefficient for OCR, which is a deterministic task with strong local dependencies (e.g., table syntax)
- Small-scale models typically suffer from hallucinations and repetition when processing complex layouts without explicit structural guidance
Concrete Example:
When processing a complex table, a standard small VLM might hallucinate the reading order or generate broken Markdown tags due to a lack of planning. GLM-OCR avoids this by first cropping the table region (via layout analysis) and then using Multi-Token Prediction to generate coherent structural tags (e.g., `<td>...</td>`) in blocks, reducing syntax errors.
Key Novelty
Compact Layout-Aware MTP Architecture
- Integrates a standalone layout analysis module (PP-DocLayout-V3) before the generative model to decompose complex pages into simpler regions, preventing reading order confusion
- Employs Multi-Token Prediction (MTP) during both training and inference, allowing the model to predict multiple tokens per step (5.2 effective tokens/step) to boost speed and structural consistency
- Unifies Document Parsing (transcription) and Key Information Extraction (KIE) into a single conditional generation framework handled by a compact 0.9B model
Architecture
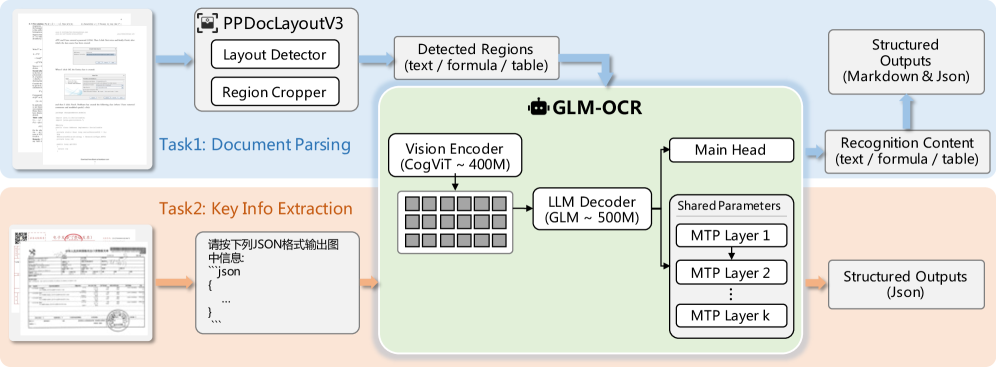
The overall GLM-OCR system architecture, illustrating the Vision Encoder, LLM Decoder, and the Multi-Token Prediction heads.
Evaluation Highlights
- Achieves 94.6 on OmniDocBench v1.5, ranking first among all evaluated models including larger general VLMs and specialized peers like PaddleOCR-VL-1.5
- Attains 93.7 on Nanonets-KIE, setting a new state-of-the-art for open-source models and outperforming GPT-5.2 (87.5)
- Delivers ~50% inference throughput improvement (5.2 tokens/step) via Multi-Token Prediction compared to standard autoregressive decoding
Breakthrough Assessment
8/10
Significant engineering achievement in efficiency/performance trade-offs. Successfully adapts Multi-Token Prediction to OCR and beats much larger models with a sub-1B parameter footprint.