📊 Experiments & Results
Evaluation Setup
Safety-constrained alignment tasks balancing helpfulness and harmlessness
Benchmarks:
- Not explicitly named in text (Safety/Helpfulness Trade-off)
Metrics:
- Helpfulness (Reward)
- Harmlessness (Cost)
- Spectral Risk Measures (e.g., CVaR)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| The paper claims improvements in harmlessness and robustness but the provided text excerpt does not contain specific numeric tables or extracted values. The results are described qualitatively. | ||||
Experiment Figures
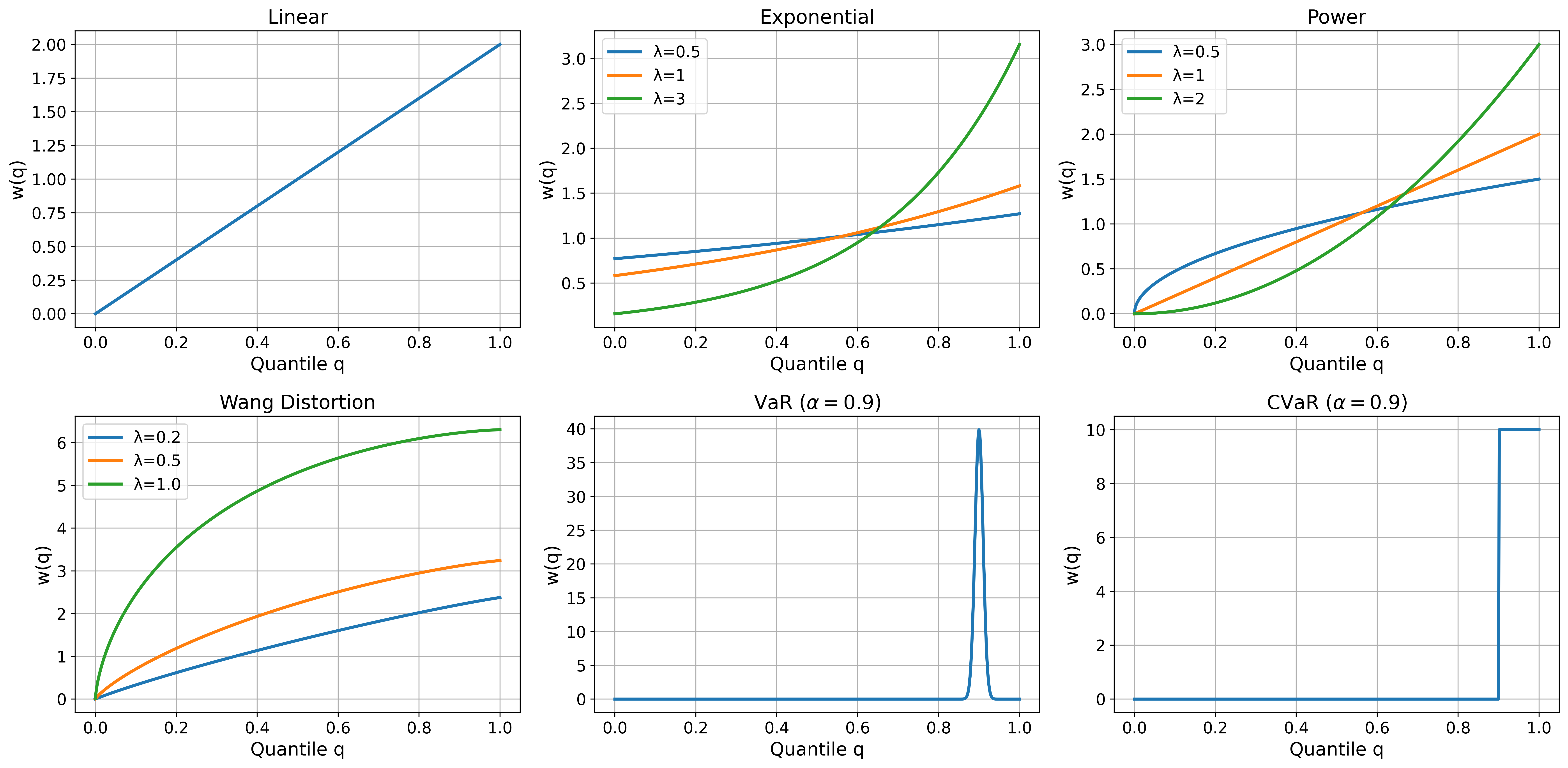
Illustrates spectral weighting functions for different Spectral Risk Measures (SRMs) like Expectation, CVaR, and generic spectral risks
Main Takeaways
- RAD yields models more robust to safety violations (lower tail risk) compared to Safe RLHF
- Achieves competitive helpfulness while enforcing stricter distributional safety constraints
- Quantile weighting allows principled tuning of the risk profile (e.g., recovering CVaR or Mean constraints)
- Shows greater robustness on out-of-distribution harmlessness evaluations