📝 Paper Summary
Dexterous Manipulation
Exploration in Reinforcement Learning
Intrinsic Rewards
CCGE enables general-purpose dexterous manipulation learning by rewarding agents for discovering novel contact patterns between specific fingers and object regions, conditioned on learned object state clusters.
Core Problem
Dexterous manipulation lacks a standard, general-purpose reward signal; existing methods rely on brittle task-specific priors or generic novelty metrics (state/dynamics) that fail to incentivize meaningful physical contact.
Why it matters:
- Task-specific rewards (shaping) do not generalize, requiring manual engineering for every new task (e.g., singulation vs. reorientation)
- Generic exploration methods (e.g., maximizing prediction error) often lead to task-irrelevant behaviors like waving hands in free space without touching the object
- Force-based curiosity is unstable due to the non-smooth, discontinuous nature of contact forces in manipulation
Concrete Example:
In a reorientation task, a standard novelty-seeking agent might wave its fingers near the object to maximize state variance without touching it. CCGE specifically rewards the agent only when a finger touches a previously untouched region of the object surface.
Key Novelty
Contact Coverage-Guided Exploration (CCGE)
- Explicitly models contact alignment as pairings between hand fingers and discretized object surface regions
- Maintains a 'coverage counter' that tracks how often each finger has touched each object region, rewarding rare pairings
- Contextualizes exploration using a learned hash of the object state, ensuring that contact strategies learned in one configuration (e.g., grasping) don't suppress exploration in another (e.g., reorienting)
Architecture
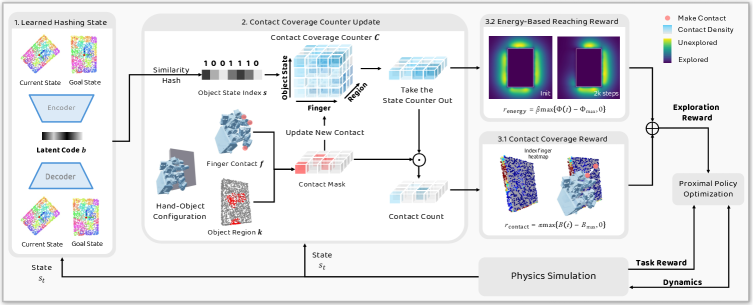
Overview of the CCGE pipeline showing the flow from state input to reward generation
Evaluation Highlights
- Substantially improves training efficiency and success rates over existing exploration methods (qualitative finding from abstract)
- Learned contact patterns transfer robustly to real-world robotic systems (qualitative finding from abstract)
- Demonstrated across diverse tasks: cluttered object singulation, constrained object retrieval, in-hand reorientation, and bimanual manipulation
Breakthrough Assessment
8/10
Addresses a critical bottleneck in robotic manipulation—the lack of general-purpose rewards. By formalizing 'contact coverage', it offers a principled alternative to heuristic reward shaping.