📊 Experiments & Results
Evaluation Setup
Evaluation of 32 LLMs by 3 frontier judges on 100 prompts across 11 temperature settings
Benchmarks:
- WritingBench (Subset) (Open-ended text generation (Literature, Education, Academic, Finance, Politics, Mixed))
Metrics:
- Pearson correlation (r) (Sample-level agreement)
- Spearman rank correlation (rho) (Model-level agreement)
- Intraclass Correlation Coefficient (ICC) (Absolute agreement)
- Knowledge-Grounding Diagnostic (Delta K)
- Statistical methodology: Paired t-tests (Bonferroni-corrected, alpha=0.05/k); Cohen's d for effect sizes
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Diagnostic results showing that injecting knowledge (MERG) significantly reduces the 'illusory' agreement found in baselines. | ||||
| WritingBench (Subset) | Pearson r (DeepSeek-R1 evaluation) | 0.643 | 0.426 | -0.217 |
| WritingBench (Subset) | Pearson r (Qwen3-235B evaluation) | 0.667 | 0.529 | -0.138 |
| Domain analysis showing that knowledge injection increases agreement in objective fields but decreases it in subjective ones. | ||||
| WritingBench (Education) | Delta K (Agreement Change) | 0.00 | 0.22 | +0.22 |
| WritingBench (Literature) | Delta K (Agreement Change) | 0.00 | -0.06 | -0.06 |
| Resolution Paradox results showing high model-level ranking agreement coexisting with mediocre sample-level agreement. | ||||
| WritingBench (Subset) | Spearman rho (Model-level) | 0.72 | 0.989 | +0.269 |
| WritingBench (Subset) | Pearson r | 0.24 | 0.62 | +0.38 |
Experiment Figures
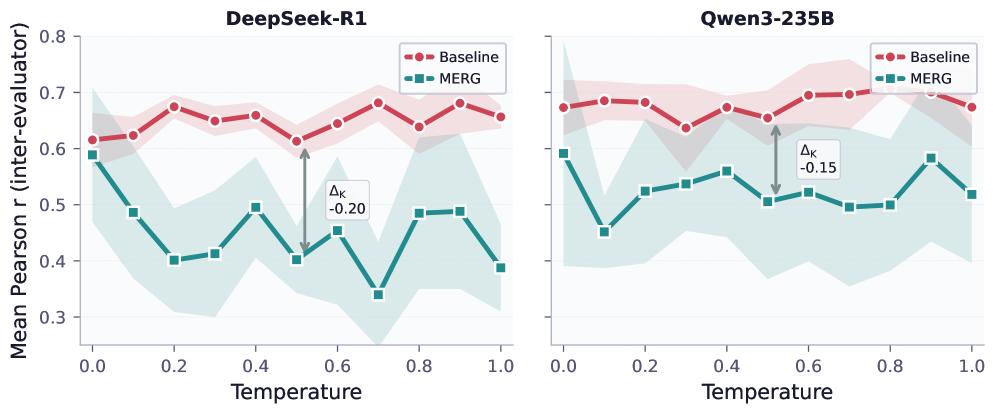
Inter-evaluator agreement (Pearson r) across 11 temperature settings for baseline vs. MERG
Main Takeaways
- The 'Shared Illusion' exists: High inter-evaluator agreement is often an artifact of shared training biases and surface heuristics (formatting, tone) rather than shared understanding of quality.
- Resolution Paradox: Evaluators are reliable for coarse-grained model ranking (Base vs Thinking) but unreliable for the fine-grained per-sample scoring required for RLAIF reward signals.
- Rubric Commensurability: Much of the reported reliability in literature comes from sharing the rubric *structure* (dimension names); when rubrics are generated independently, agreement collapses.
- Negative correlation between quality and agreement: Evaluators agree most on low-quality (Base) models and least on high-quality (Thinking) models, precisely where discrimination is most needed.