📝 Paper Summary
Video-to-Music Generation
Multimodal Generation
Zero-shot Learning
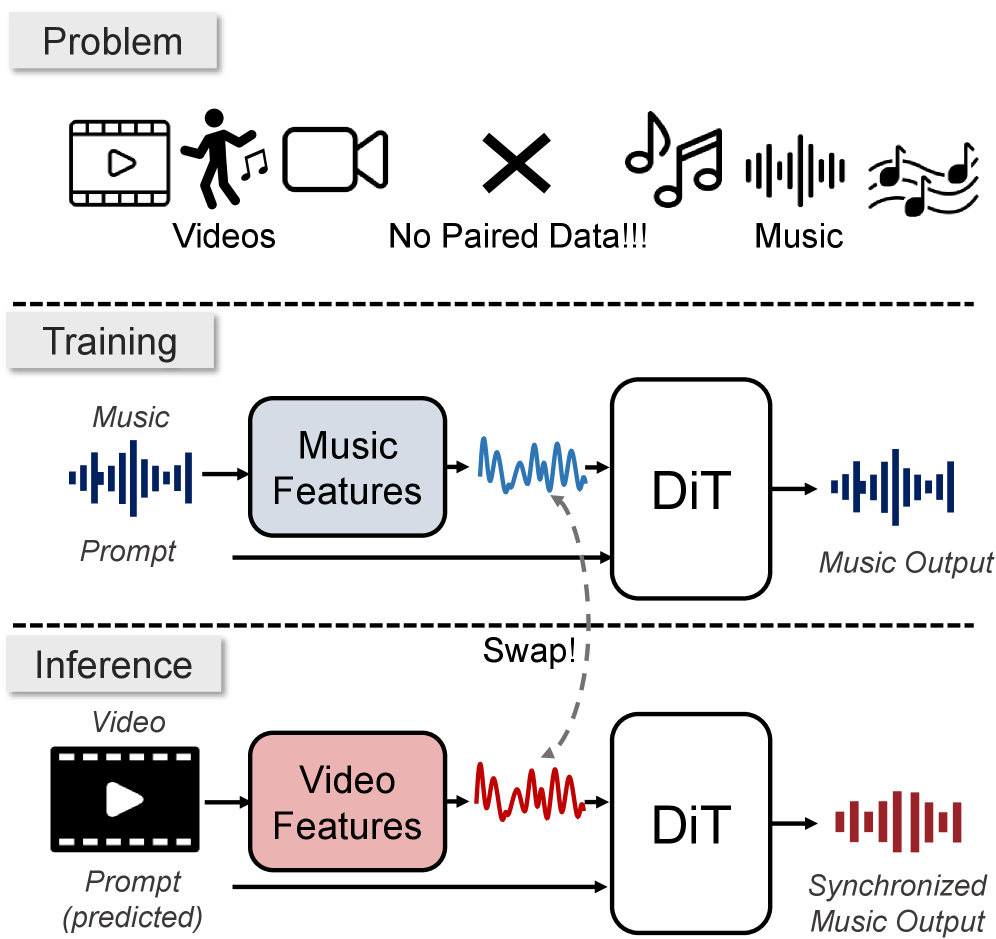
V2M-Zero enables temporally synchronized video-to-music generation without paired training data by aligning intra-modal event curves—representations of when change occurs—across video and music modalities.
Core Problem
Existing text-to-music models lack fine-grained temporal control for video, and current video-to-music models require large paired datasets that are often noisy or copyright-restricted.
Why it matters:
- Content creators currently must manually edit videos to fit generated music, a tedious process hindering real-world adoption
- Paired video-music datasets from the internet often contain vocals, imperfect mixing, or entangle semantic and temporal controls, limiting high-fidelity generation
- Bridging modalities via text prompts alone (using LLMs) captures mood but fails to specify exact timing of beats or scene cuts
Concrete Example:
In a product promotion video, musical cues (beats, dynamic changes) must align exactly with visual reveals or motion highlights. Current T2M models might generate the right 'upbeat' style but place the beat drops at random times unrelated to the visual cuts.
Key Novelty
Zero-Pair Synchronization via Event Curves
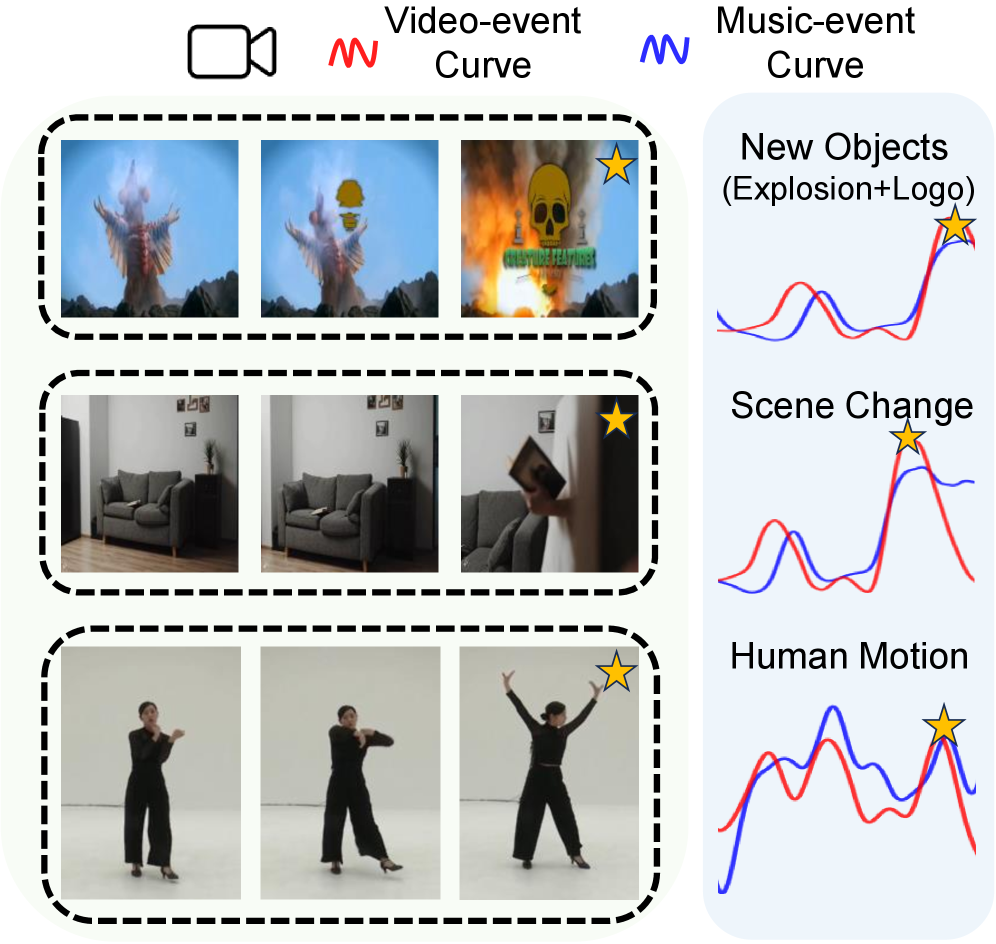
- Decouples 'when' change occurs from 'what' changes: uses intra-modal similarity (self-similarity) to create 1D event curves that represent the tempo/structure of change independently of the modality (video or music)
- Trains a music generator conditioned on music-derived event curves, then swaps in video-derived event curves at inference time to achieve synchronization without ever seeing paired video-music data
Architecture
The training and inference pipeline. Left side: Training on music with MusicFM extracting curves. Right side: Inference on video with Visual Encoder extracting curves. Center: The Flow Matching Transformer.
Evaluation Highlights
- +21% to +52% improvement in temporal synchronization (interactive alignment) over paired-data baselines across OES-Pub, MovieGenBench-Music, and AIST++
- +28% higher beat alignment specifically on AIST++ dance videos compared to baselines
- 5–21% higher audio quality (FAD/CLAP scores) compared to supervised methods trained on paired data
Breakthrough Assessment
8/10
Significantly outperforms supervised baselines without using paired data, offering a clever structural solution (event curves) to the modality gap. Solving fine-grained synchronization zero-shot is a strong contribution.