📝 Paper Summary
3D Generative Models
Latent 3D Representations
Neural Rendering
LiTo introduces a 3D latent representation that encodes the surface light field into compact tokens, enabling the generation of 3D objects with realistic view-dependent effects like specular highlights.
Core Problem
Most existing latent 3D representations capture only geometry or view-independent diffuse color, failing to represent realistic material effects like reflections and highlights.
Why it matters:
- Realistic objects have complex materials (smooth, rough, translucent) that appear different from different viewing angles
- Current generative models struggle to produce photorealistic assets because they simplify appearance to diffuse textures
- Accurate light-matter interaction is essential for high-quality 3D asset creation in gaming, VR, and design
Concrete Example:
When generating a shiny ceramic vase from an image, existing methods like TRELLIS produce a matte surface where reflections are 'baked in' as static texture. LiTo generates a surface where the specular highlight moves correctly as the camera rotates.
Key Novelty
Surface Light Field Tokenization (LiTo)
- Encodes random subsamples of a surface light field (points + view direction + radiance) into a set of latent vectors rather than just encoding geometry or static color
- Uses a specialized encoder to interpolate missing light field samples, allowing the model to learn a continuous representation of view-dependent appearance from sparse inputs
- Decodes into 3D Gaussians with higher-order spherical harmonics to explicitly render complex lighting effects like Fresnel reflections
Architecture
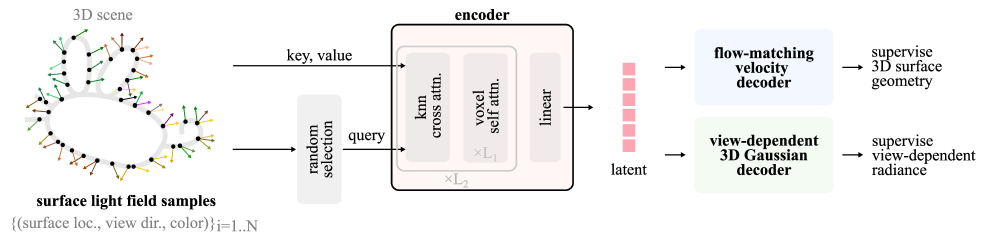
The complete pipeline: Surface Light Field Sampling -> Encoder -> Latent Representation -> Decoders (Geometry & Gaussian)
Evaluation Highlights
- Outperforms TRELLIS and TripoSR on visual quality metrics (LPIPS, PSNR) for single-image reconstruction
- Achieves higher input fidelity than state-of-the-art methods while maintaining geometric accuracy
- Demonstrates capability to generate view-dependent effects (specular highlights) that move consistently with camera viewpoint, unlike baseline methods
Breakthrough Assessment
8/10
Significant step forward in 3D generative modeling by successfully integrating view-dependent appearance into a latent space, addressing a major limitation of current geometry-focused or diffuse-only methods.
