📝 Paper Summary
Knowledge Distillation
Curriculum Learning
LLM Reasoning
Paced improves LLM distillation efficiency and stability by weighting training examples using a Beta kernel derived from the student's pass rate, concentrating effort on problems at the frontier of competence.
Core Problem
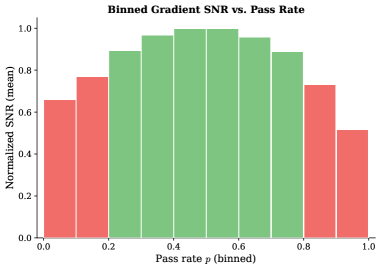
Standard distillation spreads compute uniformly, wasting resources on mastered problems (vanishing gradients) and intractable ones (high-variance, incoherent gradients that cause forgetting).
Why it matters:
- Uniform training forces models to process samples that provide no signal or actively harmful noise, slowing convergence
- High-variance gradients from intractable problems erode existing capabilities, leading to catastrophic forgetting on benchmarks like MMLU
- Curriculum learning usually relies on static difficulty heuristics, but true difficulty depends on the specific student's evolving state
Concrete Example:
In standard distillation, a student might be forced to train on a math problem it has 0% chance of solving. The resulting gradients are large but directionally random, damaging the weights established for easier problems. Conversely, training on a problem it solves 100% of the time yields near-zero gradients, wasting compute.
Key Novelty
Proficiency-Adaptive Competence Enhanced Distillation (Paced)
- Dynamically weights each training example based on the student's pass rate p using a Beta kernel w(p) = p^α(1-p)^β
- Derives this specific weight shape theoretically by proving that gradient Signal-to-Noise Ratio (SNR) naturally vanishes at both p=0 and p=1
- Combines forward KL (mode coverage) and reverse KL (mode consolidation) in a two-stage schedule to maximize reasoning performance while minimizing forgetting
Architecture
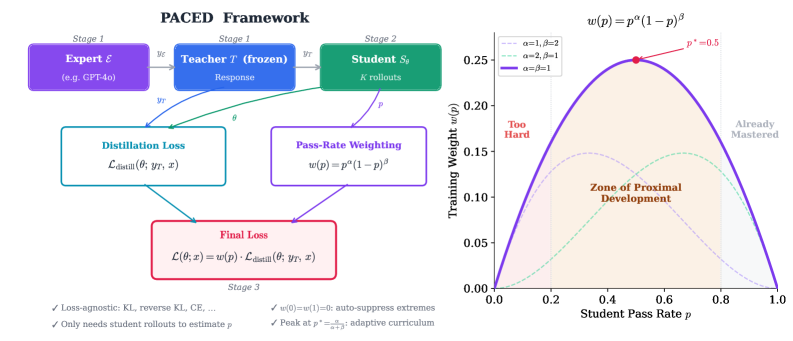
Overview of the Paced framework illustrating the selection of training samples based on the Zone of Proximal Development.
Evaluation Highlights
- +14.8% accuracy on AIME 2025 for Qwen3-8B distilled from Qwen3-14B using Paced (forward KL)
- +16.7% accuracy on AIME 2025 using a two-stage schedule (forward then reverse KL), demonstrating synergy between coverage and consolidation
- Maintains MMLU forgetting at just 0.2%, significantly better than standard uniform baselines
Breakthrough Assessment
8/10
Strong theoretical grounding for curriculum design combined with impressive empirical gains on hard reasoning tasks and minimal forgetting. The derivation from SNR boundary conditions distinguishes it from heuristic weighting.