📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation on general STEM and Math reasoning benchmarks.
Benchmarks:
- MMLU-Pro (General knowledge & reasoning (10 choices))
- GPQA-Diamond (Expert-level science QA)
- SuperGPQA (Broad disciplinary science QA)
- BBEH (Complex multi-type reasoning (BIG-Bench Extra Hard))
Metrics:
- Pass@1 (Accuracy)
- Reward Score (during training)
- Response Length
- Policy Entropy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparative analysis of training paradigms shows SFT outperforms pure RL on base models, but the DeReason decoupled curriculum achieves the best overall performance. | ||||
| GPQA-Diamond | Pass@1 | Not reported in the paper | Not reported in the paper | Not reported in the paper |
Experiment Figures
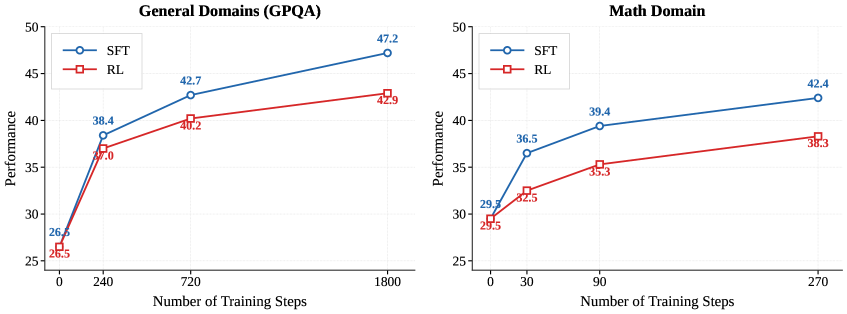
Comparison of SFT vs. RL performance vs. Data Size on GPQA-Diamond and Math tasks.
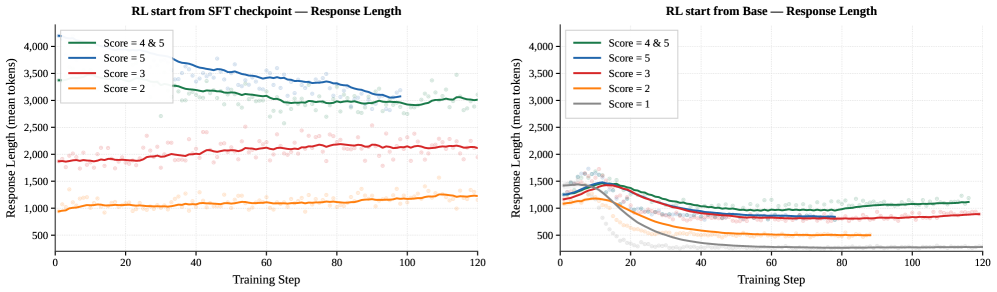
Evolution of response length during RL training broken down by reward score.
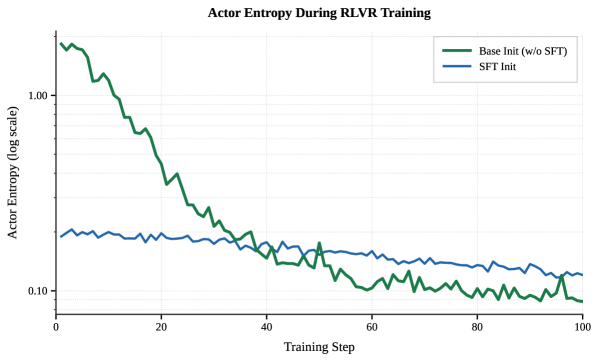
Actor entropy evolution during training.
Main Takeaways
- SFT is consistently superior to pure RLVR for base models on general reasoning tasks, likely due to better knowledge acquisition efficiency.
- Difficulty-based partitioning (DeReason) outperforms random partitioning for SFT-then-RL pipelines, validating the curriculum strategy.
- RL training from a base model leads to higher entropy collapse and extreme length bifurcation compared to RL from an SFT checkpoint.
- The method is effective on both Math and General STEM domains, with larger gains on reasoning-intensive benchmarks (BBEH) than knowledge-intensive ones (MMLU-Pro).