📝 Paper Summary
Efficient Multimodal Learning
Visual Token Compression
FMVR enables multimodal models to maintain high accuracy with drastically reduced visual tokens by decomposing compressed features into frequency bands to restore both salient and subtle visual semantics.
Core Problem
Reducing the number of visual tokens in Large Multimodal Models (LMMs) to save compute causes a loss of fine-grained visual details, leading to poor reasoning on detailed images.
Why it matters:
- Computational cost and memory usage of LMMs increase quadratically with token count, limiting deployment in resource-constrained or real-time scenarios
- Existing compression methods (like Q-Former) produce fixed-length outputs, lacking the flexibility to dynamically adjust trade-offs between speed and accuracy at runtime
- Simple token pruning often discards subtle 'anti-salient' information (like small background objects) that is crucial for complex visual reasoning
Concrete Example:
In a Grad-CAM visualization (Fig. 2), reducing visual tokens from 576 to 36 without restoration causes the model to lose focus on nuanced regions, leading to hallucinations. With FMVR, the model correctly answers questions even with reduced tokens by recovering these attention patterns.
Key Novelty
Frequency-Modulated Visual Restoration (FMVR)
- Decomposes visual representations into low- and high-frequency components using parallel AvgPool and MaxPool branches
- Uses the AvgPool branch to enhance 'salient' (dominant) visual semantics and the MaxPool branch to recover 'anti-salient' (weak/subtle) semantics that are usually lost during compression
- Integrates with Matryoshka Representation Learning to create nested visual token sets (e.g., 1, 9, 36, 144, 576), allowing elastic inference at varying computational budgets
Architecture
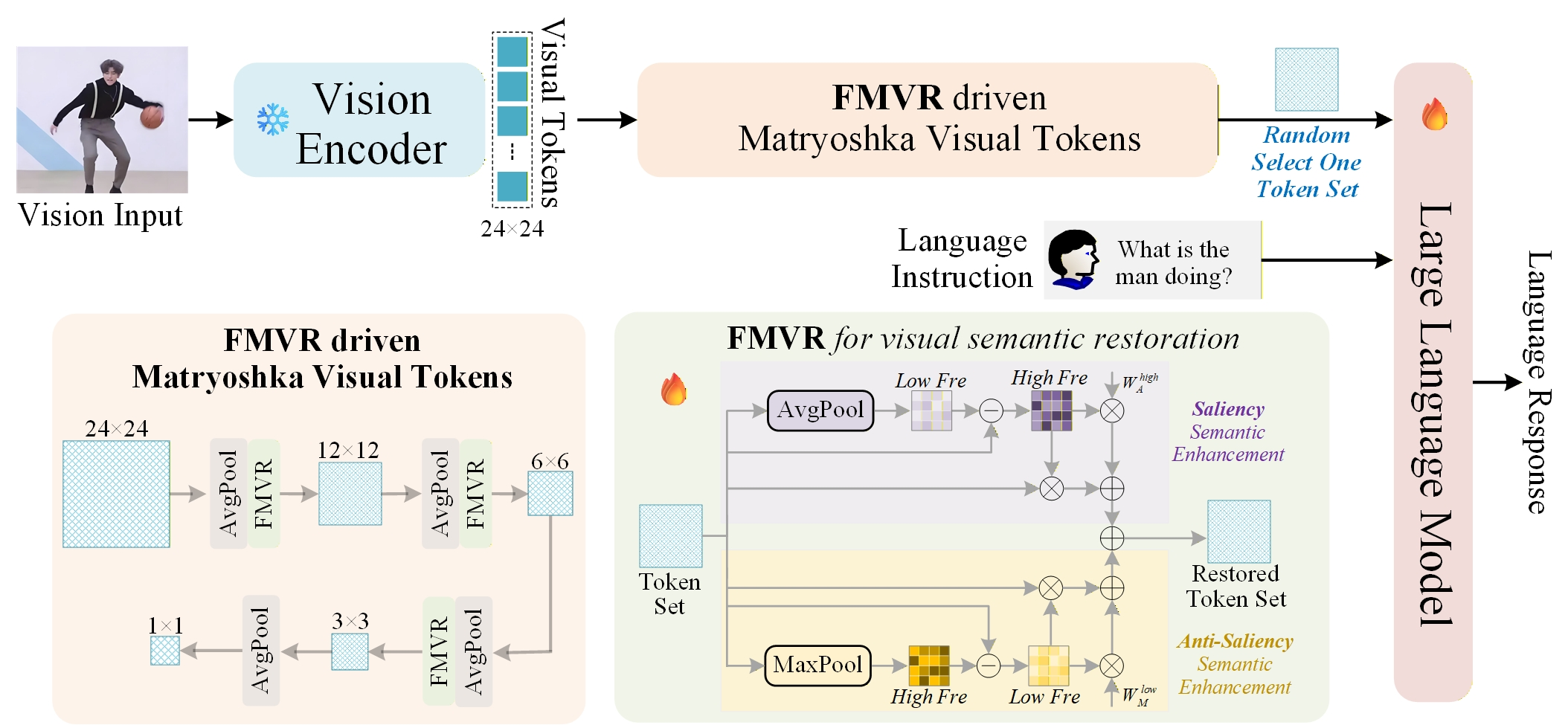
The FMVR-LLaVA architecture, detailing the injection of the FMVR module into the visual encoder's pooling stages.
Evaluation Highlights
- Reduces FLOPs by 89% (using 36 visual tokens) while maintaining ~100% of the original LLaVA-1.5-7B accuracy across 10 benchmarks
- Outperforms FastV by 1.8% and 7.0% when using only 1 visual token on image benchmarks
- Outperforms Video-LLaVA by 5.1% on Video-based Question-Answer benchmarks while using only 180 visual tokens
Breakthrough Assessment
8/10
Significantly decouples model performance from token count, solving a major efficiency bottleneck in LMMs. The frequency-based restoration offers a novel, lightweight mechanism to retain semantic density in compressed representations.

