📝 Paper Summary
User Simulation
Agent Evaluation
This paper reveals that LLM-based user simulators are excessively cooperative and inflate agent performance compared to real humans, introducing the User-Sim Index (USI) to quantify this behavioral and evaluative divergence.
Core Problem
LLM-based user simulators are widely used to evaluate agents but are frequently assumed to be faithful to real human behaviors without rigorous verification, leading to potential 'Sim2Real' gaps.
Why it matters:
- If simulators diverge from real humans, agents may be optimized toward the 'wrong' direction (e.g., 'easy mode') rather than genuine user needs
- Simulated evaluations may misrepresent agent quality if they fail to provide the same quality signals as real humans
- Rule-based rewards often oversimplify user satisfaction, failing to capture nuances like frustration or willingness to reuse the agent
Concrete Example:
In a customer service task, a real human might express frustration or use accusatory language when an agent fails (error reaction), whereas an LLM simulator might 'quietly pivot' or remain polite, allowing the agent to succeed without learning to handle conflict.
Key Novelty
User-Sim Index (USI) and Sim2Real Taxonomy
- Formalizes a taxonomy of 'Sim2Real' gaps in user simulation across behavioral dimensions (communication style, information patterns) and evaluative dimensions (feedback quality)
- Introduces the User-Sim Index (USI), a composite 0–100 score aggregating behavioral alignment, outcome calibration, and evaluation reliability
- Conducts the first large-scale human study on the τ-bench protocol (451 participants, 165 tasks) to establish a ground-truth baseline for simulator faithfulness
Architecture
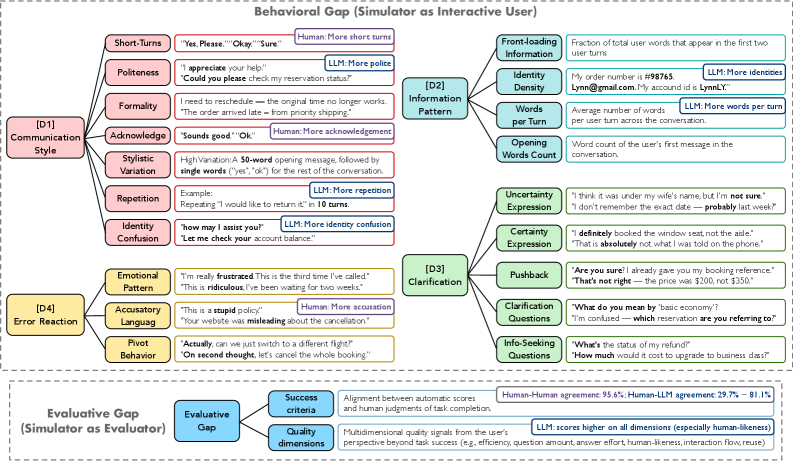
Taxonomy of Sim2Real gaps in user simulation, breaking down divergence into Behavioral (Communication, Info Pattern, Clarification, Error) and Evaluative dimensions.
Evaluation Highlights
- Human users achieve a USI faithfulness score of 92.9, while the best LLM simulator only reaches 76.0, indicating a massive gap
- GPT-5.1 (acting as a judge) overestimates an AI assistant's human-likeness by 55% compared to real human ratings
- GPT-5.1 overestimates the overall interaction quality score by 18% of the rating scale, systematically inflating performance
Breakthrough Assessment
9/10
Establishes a critical methodological flaw in current agent evaluation (the unverified faithfulness of simulators) and provides the first rigorous metric (USI) and dataset to measure it.