📊 Experiments & Results
Evaluation Setup
Infer political alignment (Rep/Dem) from text posts in Debate.org (DDO) and Reddit
Benchmarks:
- Debate.org (DDO) (Binary Classification (Self-identified labels))
- Reddit (Binary Classification (Community-inferred labels)) [New]
Metrics:
- Macro F1 score
- Statistical methodology: Bootstrap-based paired t-tests reported for aggregation method comparisons
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| User-level inference results showing LLMs can accurately predict politics from 'General' (non-political) text, especially when using confidence-aware aggregation. | ||||
| Macro F1 | 0.606 | 0.799 | +0.193 | |
| Debate.org (DDO) | Macro F1 | 0.619 | 0.685 | +0.066 |
| Comparison against traditional supervised machine learning baselines shows LLMs achieve superior performance without training. | ||||
| Debate.org (DDO) | Macro F1 | 0.612 | 0.647 | +0.035 |
Experiment Figures
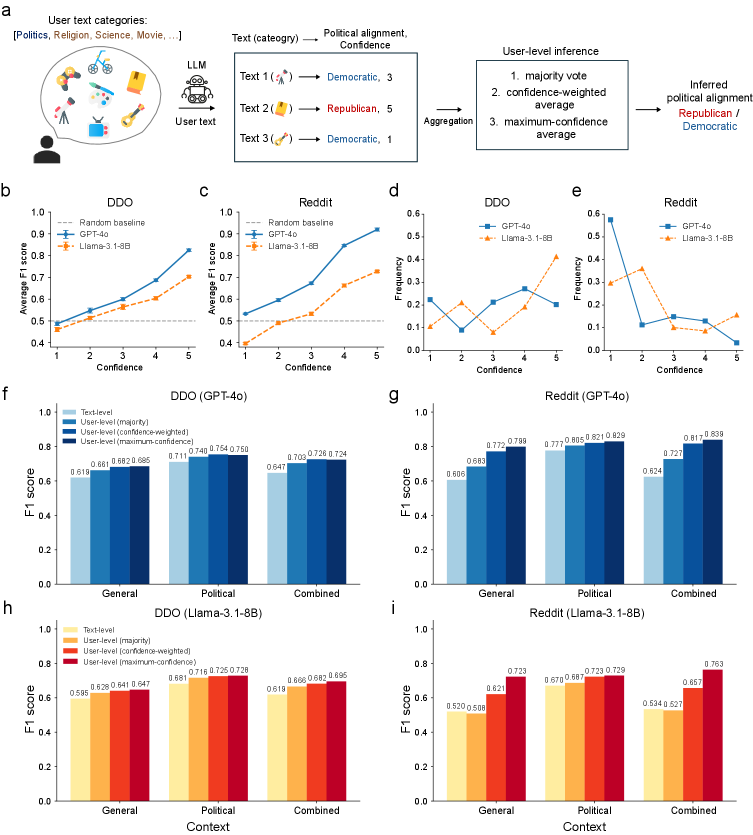
Performance (F1 scores) at text-level vs confidence, and user-level aggregation results.
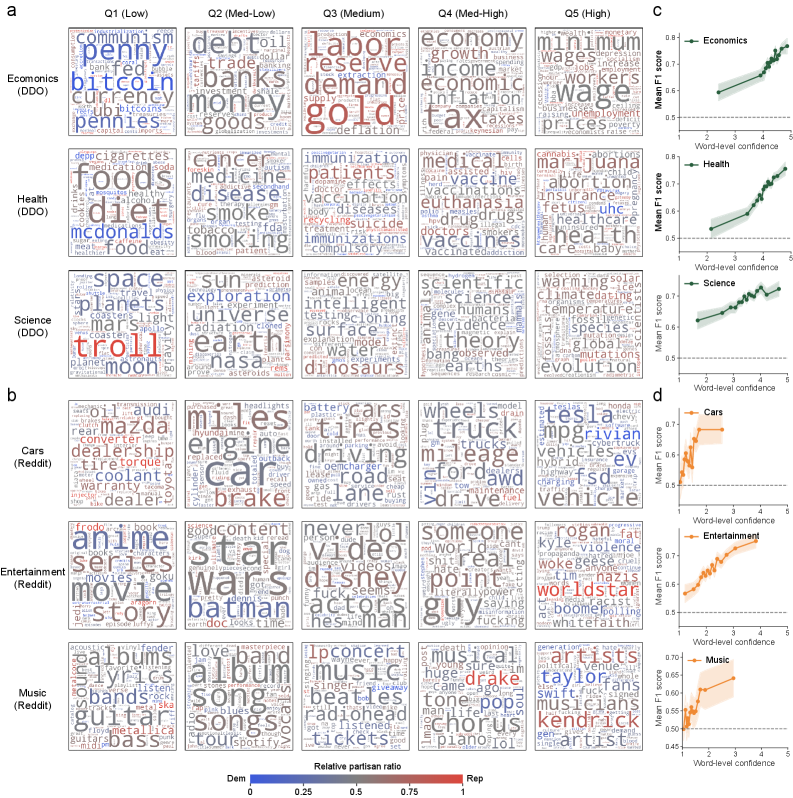
Word clouds and word-level confidence analysis for specific categories (e.g., Cars, Music).
Main Takeaways
- LLMs can infer political alignment from general, non-political topics (e.g., Health, Science, Cars) with high accuracy, often matching inference from explicit political text.
- Model confidence is a highly reliable calibrator: accuracy increases significantly when filtering for high-confidence predictions.
- Inference performance correlates with the semantic similarity of a topic to politics and the overlap of its user base with political communities.
- Models leverage specific 'politicized' keywords (e.g., 'Tesla', 'Taylor Swift', 'Latte') that carry latent socio-cultural signals, not just explicit political terminology.