📝 Paper Summary
Agentic Search
Reinforcement Learning for LLMs
Meta-Learning
MR-Search trains search agents to perform in-context self-reflection by treating a sequence of interaction attempts as a single meta-episode, enabling the model to learn how to recover from errors without dense manual supervision.
Core Problem
Standard RL search agents rely on sparse outcome rewards at the end of a single trajectory, making it difficult to assign credit to intermediate steps and leading to inefficient exploration.
Why it matters:
- Agents often get stuck in local optima because independent episodes do not share context or learn from immediate past failures
- Process reward models (providing intermediate feedback) require expensive external annotations or unreliable proxy models
- Multi-turn interactions with tools amplify small errors, obscuring which specific action led to a failure
Concrete Example:
In a multi-hop QA task, an agent might retrieve the wrong document in step 1. In standard RL, the entire episode gets a zero reward. The agent doesn't know *why* it failed. In MR-Search, the agent generates an answer, reflects on the potential error, and tries again *in the same context*. The meta-policy is optimized to make this reflection-revision process effective.
Key Novelty
Meta-RL with In-Context Self-Reflection
- Redefines the RL optimization unit: instead of one episode = one attempt, a 'meta-episode' consists of a sequence of attempts separated by self-reflection steps
- Uses a multi-turn advantage estimation that credits earlier reflection steps if they lead to a correct answer in a later attempt within the same meta-episode
- Learns to learn: The policy is trained to utilize the history of its own past failures in the context window to improve subsequent search strategies
Architecture
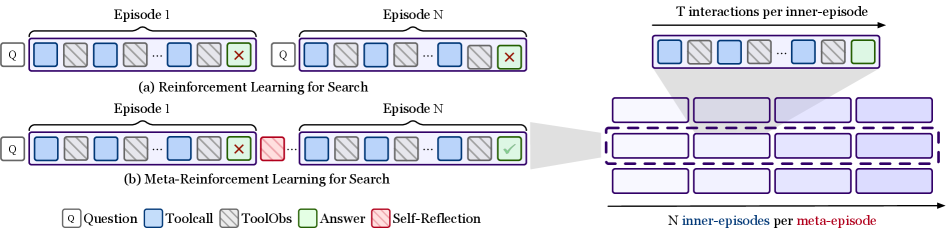
Comparison between Standard RL (left) and MR-Search (right). Standard RL treats episodes as independent isolated attempts. MR-Search links episodes sequentially: Episode 1 -> Reflection -> Episode 2, forming a single meta-episode.
Evaluation Highlights
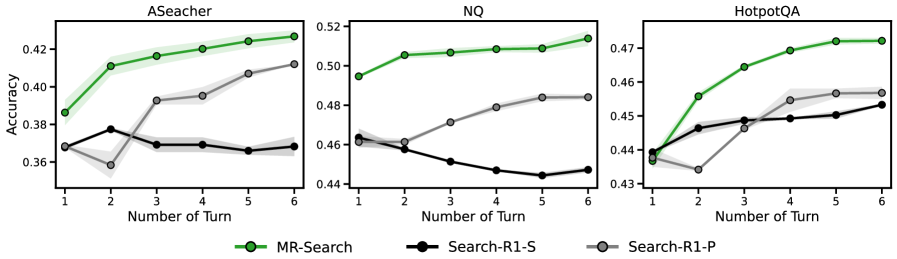
- Achieves 19.3% average relative improvement over baselines on Qwen2.5-3B-Base across eight benchmarks
- Achieves 9.2% average relative improvement on Qwen2.5-7B-Base, demonstrating scalability across model sizes
- Generalizes effectively across diverse tasks including NQ, TriviaQA, and complex multi-hop datasets like HotpotQA and ASearcher
Breakthrough Assessment
8/10
Significantly reframes agent training from single-shot success to meta-learning correction strategies. Addresses the critical sparse reward problem in agentic search without needing expensive process supervision.