📝 Paper Summary
Self-evolving Agentic reasoning
Neuro-symbolic AI
This approach uses an LLM to identify missing planning operators for novel objects and generates dense reward functions to guide reinforcement learning agents in learning the necessary control policies.
Core Problem
Traditional symbolic planners fail when novel objects appear because the planning domain lacks the specific operators needed to interact with them, and standard RL exploration is too inefficient to discover these operators from scratch.
Why it matters:
- Common everyday objects introduced into a robot's environment often disrupt pre-defined planning domains, causing autonomous agents to fail.
- Existing hybrid methods rely on random RL exploration to discover missing operators, which scales poorly in continuous domains where plannable states are hard to reach by chance.
- Current approaches either assume fully specified domains or commit to single reward functions that may mislead training.
Concrete Example:
In a 'Coffee-Drawer' task, a pod is inside a closed drawer. A standard robot knows how to pick items from a table but lacks an 'open-drawer' operator. Random exploration fails to open the drawer, so the robot cannot retrieve the pod.
Key Novelty
LLM-Guided Missing Operator Identification and Curriculum Learning
- Uses an LLM's common sense to structurally define missing PDDL operators (preconditions and effects) when a planner hits an impasse due to a novel object.
- Prompts the LLM to write dense reward functions (code) for specific sub-goals derived from the new operator's effects, creating a curriculum for RL agents.
- Runs multiple RL agents in parallel with different LLM-generated reward functions, pruning the worst performers to find a working policy.
Architecture
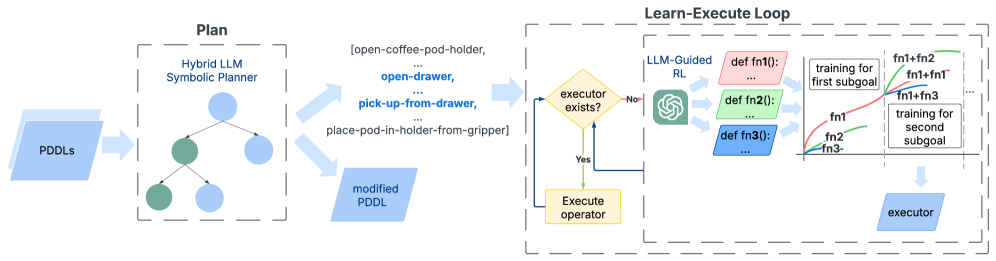
The overall Plan-Learn-Execute loop.
Evaluation Highlights
- Outperforms Operator Discovery (OD) and LEAGUE-sparse baselines across four continuous robotic manipulation domains (Kitchen, Nut Assembly, Coffee-Box, Coffee-Drawer).
- Successfully learns complex multi-stage tasks like 'Coffee-Drawer' (opening a drawer to retrieve a pod) where random exploration baselines fail completely.
- Significantly speeds up learning by using LLM-generated dense rewards compared to sparse reward baselines.
Breakthrough Assessment
8/10
Strong contribution addressing the critical 'open-world' problem in robotics. By using LLMs to hallucinate valid PDDL operators and corresponding reward code, it bridges symbolic planning and continuous RL effectively where prior methods failed.
