📝 Paper Summary
Time Series Forecasting
Foundation Models
Efficient Tokenization
TimeSqueeze is a hybrid tokenizer that adaptively patches time series based on local signal complexity, enabling efficient long-context pretraining without sacrificing fine-grained detail.
Core Problem
Existing tokenization methods for time series force a trade-off: point-wise embeddings are computationally expensive for long sequences, while fixed-size patching blurs local dynamics and struggles with heterogeneous signal complexity.
Why it matters:
- Long-context pretraining is essential for high-performance foundation models but is bottlenecked by quadratic attention costs.
- Real-world time series have varying information density (e.g., stable periods vs. rapid fluctuations), making uniform compression suboptimal.
- Inefficient tokenization limits the scalability of foundation models to thousands of timesteps, restricting their applicability in domains like finance and healthcare.
Concrete Example:
A financial time series might be stable for hours (low information) but extremely volatile for minutes (high information). A fixed patch size of 16 would waste tokens on the stable region and blur the volatile region. TimeSqueeze assigns large patches to the stable part and small patches to the volatile part.
Key Novelty
Content-Aware Dynamic Patching via SSM Encoder
- Uses a lightweight State Space Model (Mamba) encoder to process the full-resolution signal first, capturing fine details before any compression occurs.
- Dynamically determines patch boundaries based on signal volatility (relative deviation) rather than fixed intervals, allocating more tokens to complex regions and fewer to simple ones.
- Preserves absolute positional information of the original signal to maintain temporal fidelity even after variable-length compression.
Architecture
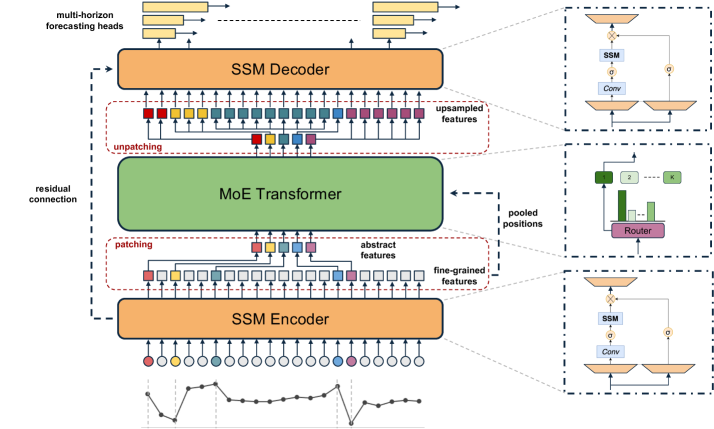
The end-to-end architecture of TimeSqueeze, illustrating the hybrid tokenization process.
Evaluation Highlights
- Achieves up to 20x faster convergence during pretraining compared to point-token baselines.
- Demonstrates 8x higher data efficiency in pretraining relative to equivalent point-token models.
- Consistently outperforms fixed-patching and point-tokenization baselines on long-horizon forecasting benchmarks in both zero-shot and full-shot settings.
Breakthrough Assessment
8/10
Addresses a critical bottleneck in time series foundation models (fixed patching vs. point-wise cost) with a theoretically grounded, adaptive solution that yields significant efficiency gains.