📝 Paper Summary
Continual Reinforcement Learning (CRL)
Model-Based Reinforcement Learning (MBRL)
Experience Replay
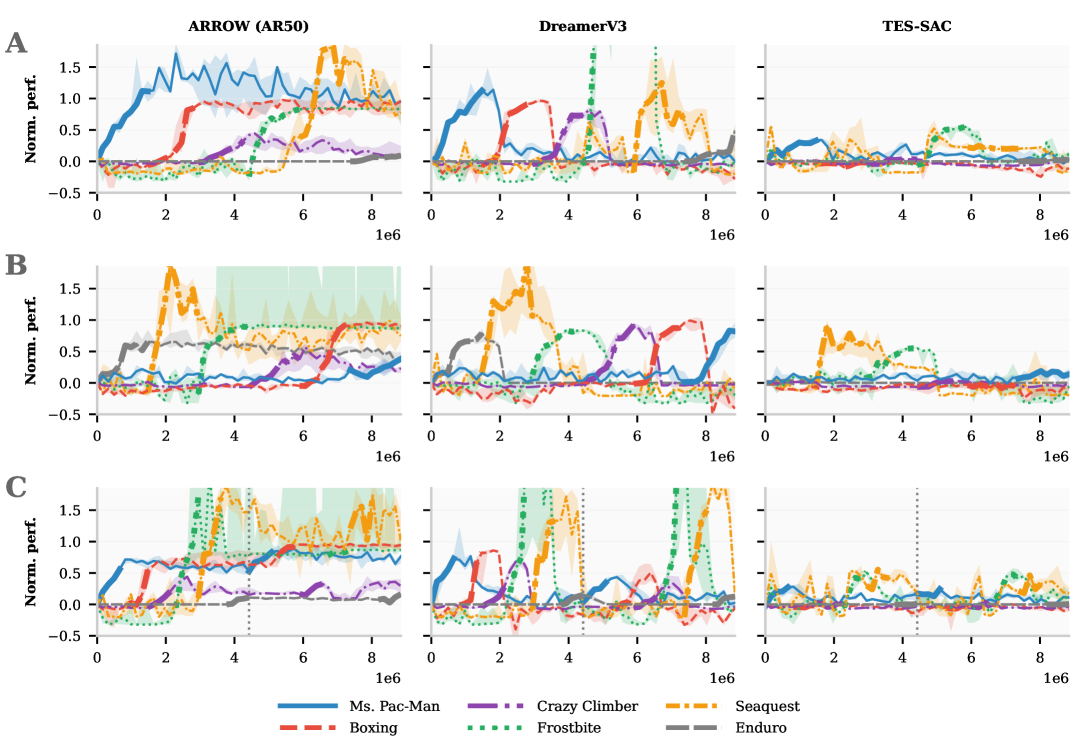
ARROW extends the DreamerV3 world model with a dual-buffer replay system that balances recent experience with long-term distribution matching to mitigate catastrophic forgetting in continual learning.
Core Problem
Continual reinforcement learning agents suffer from catastrophic forgetting when learning sequential tasks, and existing model-based solutions often require prohibitively large replay buffers to maintain performance.
Why it matters:
- Real-world agents must adapt to non-stationary environments where data is streamed and tasks do not reliably repeat
- Standard FIFO buffers in World Models overwrite old experiences, leading to rapid degradation of previously learned skills
- Existing solutions scale poorly because retaining complete experience histories demands large memory, limiting deployment on resource-constrained hardware
Concrete Example:
In a sequence of Atari games, a standard agent trained on 'Enduro' and then 'Seaquest' will overwrite the 'Enduro' memories in its FIFO buffer. As a result, its ability to play 'Enduro' collapses while it learns 'Seaquest', failing to retain the earlier skill.
Key Novelty
Augmented Replay for RObust World models (ARROW)
- Maintains two complementary replay buffers: a short-term FIFO buffer for plasticity (learning current tasks) and a long-term global distribution-matching buffer for stability (remembering past tasks)
- Uses reservoir sampling to curate the long-term buffer, ensuring it retains a representative distribution of all past experiences without growing indefinitely
- Splices experience episodes into fixed-length chunks to increase the diversity of trajectories stored within a limited memory budget
Architecture
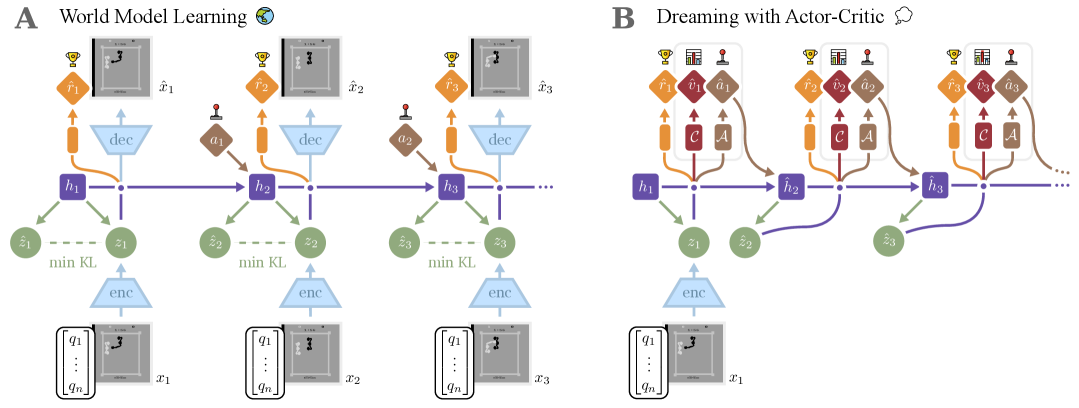
The ARROW architecture integrating the World Model, Actor-Critic, and Augmented Replay Buffer.
Evaluation Highlights
- Achieves 4x less forgetting on Atari tasks compared to DreamerV3 and SAC baselines with matched memory budgets
- Maintains comparable forward transfer capabilities to baselines while significantly improving stability
- Demonstrates robust performance on both diverse tasks (Atari) and tasks with shared structure (Procgen CoinRun variants) using only 2^19 total observations
Breakthrough Assessment
7/10
Successfully applies bio-inspired replay to modern World Models (DreamerV3) with strong empirical results on forgetting. While the components (reservoir sampling, dual buffers) are known, their integration into MBRL for efficient continual learning is novel and effective.