📝 Paper Summary
Conversational Recommendation Systems (CRS)
Agentic AI
Interactive Decision Support
IDSS utilizes entropy to quantify uncertainty in candidate sets, dynamically selecting whether to ask clarifying questions or present diverse recommendations organized by high-uncertainty attributes.
Core Problem
Users often express ambiguous or incomplete preferences (e.g., 'reliable car') early in a search, forcing systems to either ask fatiguing follow-up questions or make premature, overconfident ranking decisions.
Why it matters:
- Excessive questioning in conversational systems leads to user abandonment and fatigue
- Prematurely resolving ambiguity collapses the search space, hiding potentially viable options that don't match the system's narrow guess
- Treating elicitation, ranking, and presentation as separate optimization problems prevents consistent reasoning about uncertainty throughout the user journey
Concrete Example:
If a user asks for a 'family car' without specifying fuel type, a standard system might default to ranking gas cars highest, hiding hybrids. IDSS detects high entropy in 'fuel type' and either asks about it or presents a grid explicitly comparing Gas vs. Hybrid options.
Key Novelty
Interactive Decision Support System (IDSS)
- Uses Shannon entropy over the candidate set as a unifying signal for both elicitation (what to ask) and presentation (how to group results)
- Introduces a 'Coverage-Risk' ranking strategy that explicitly penalizes items with features the user dislikes while rewarding coverage of liked features
- Replaces flat recommendation lists with 'Exploration-Enabling Presentation,' a grid layout that organizes items along high-entropy dimensions to facilitate trade-off analysis
Architecture
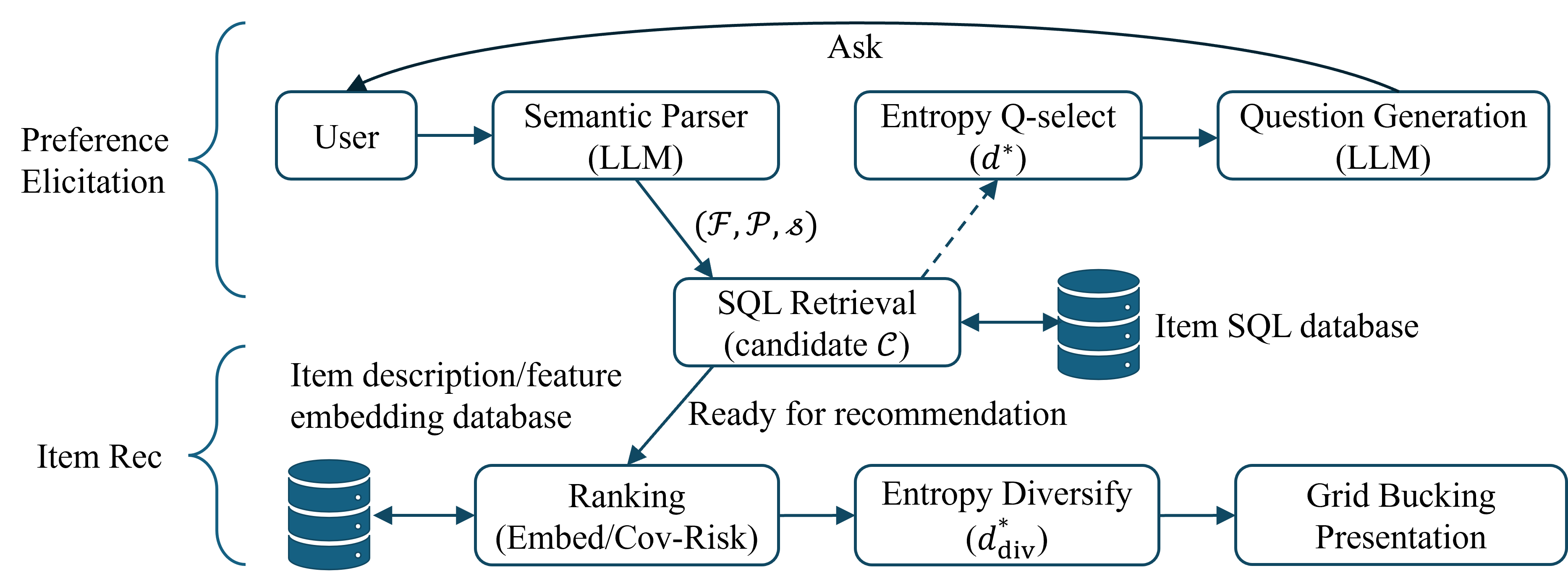
End-to-end inference architecture of IDSS, detailing the loop between user input and system response.
Breakthrough Assessment
7/10
Strong conceptual unification of elicitation and presentation via entropy. However, reliance on future/hypothetical models (GPT-5) and lack of quantitative results in the text limits full assessment.