📝 Paper Summary
Clinical Information Extraction
Synthetic Data Generation
Privacy-Preserving NLP
A framework using GPT-5 to generate task-faithful synthetic clinical letters with structured reasoning enables open-weight models to robustly extract seizure frequency from real private text.
Core Problem
Seizure frequency is critical for epilepsy care but is documented in highly variable, unstructured private text containing complex temporal patterns (ranges, clusters) that are difficult to extract and share.
Why it matters:
- Manual extraction is labor-intensive and error-prone due to implicit time anchors and diverse linguistic forms
- Privacy regulations prevent sharing real clinical narratives, creating a bottleneck for training and benchmarking high-performance NLP models
- Existing de-identification methods leave residual privacy risks, limiting the reproducibility of clinical extraction systems
Concrete Example:
A letter might state 'clusters twice monthly, 3 per cluster' or 'seizure free for 6 months'. Standard extractors struggle to normalize these ranges and cluster patterns into a single frequency, and real examples cannot be shared for training.
Key Novelty
Synthetic-Letter Framework with Structured Reasoning Supervision
- Generates full synthetic clinic letters using GPT-5, conditioned on structured label templates (rates, ranges, clusters) to ensure diverse, task-faithful linguistic patterns
- Embeds 'chain-of-thought' supervision (rationales and evidence spans) into the synthetic data, allowing student models to learn the reasoning behind complex temporal normalizations
Architecture
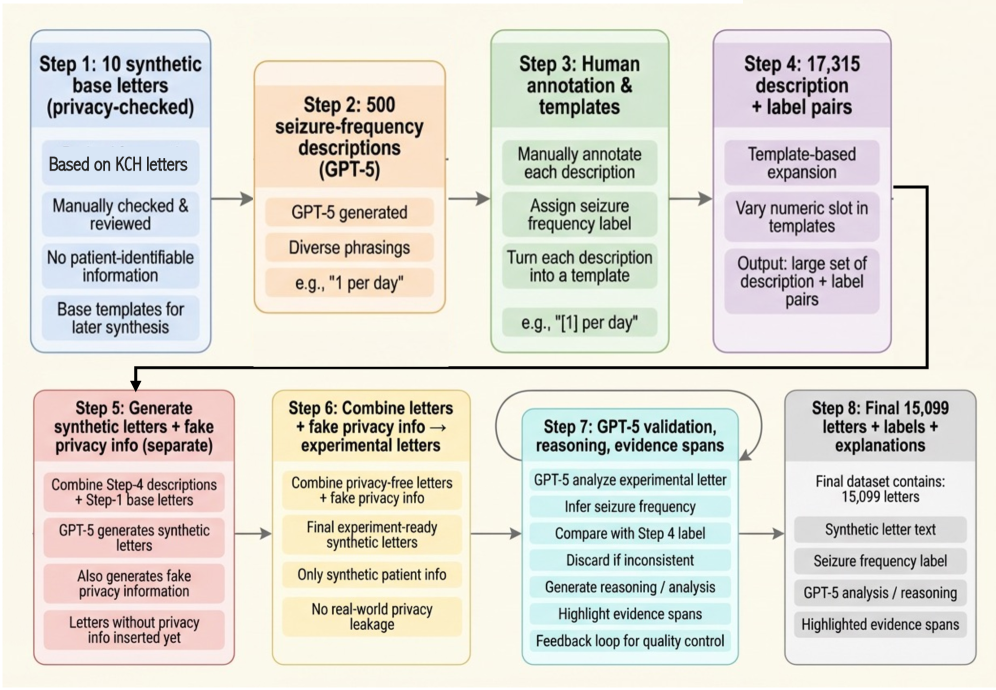
The synthetic data generation framework: from privacy-checked base letters and structured descriptions to full synthetic letters via GPT-5
Evaluation Highlights
- Models trained purely on 15,000 synthetic letters achieved 0.858 micro-F1 (Pragmatic grouping) on a held-out set of real clinical letters
- Structured label targets consistently outperformed direct numeric regression for frequency extraction
- A medically oriented 4B parameter model (MedGemma-4B-it) matched the performance of larger general-purpose models when trained on the synthetic corpus
Breakthrough Assessment
8/10
Demonstrates that fully synthetic data from a high-capacity teacher (GPT-5) can effectively substitute for real private data in a complex clinical extraction task, solving a major privacy bottleneck.