📝 Paper Summary
Multi-agent
Agentic RAG pipeline
VMAO coordinates specialized agents via a directed acyclic graph plan and an independent verification loop that detects missing information and triggers adaptive replanning before final synthesis.
Core Problem
Existing multi-agent frameworks lack principled quality verification at the orchestration level; they often fail to detect when sub-tasks are incomplete or errored before synthesizing a final answer.
Why it matters:
- Complex domains like market research require aggregating scattered data (financial, operational, competitive); missing one aspect invalidates the whole analysis
- Current systems rely on debate or role-play which improve reasoning but don't explicitly verify task completeness against the original plan
- Production systems need reliability without constant human oversight, requiring automated mechanisms to decide when to stop iterating
Concrete Example:
In a query requiring financial, operational, and competitive data, a static pipeline might fail to retrieve financial metrics due to a tool error but proceed to synthesis anyway, resulting in a partial answer. VMAO's verifier detects the missing financial node and triggers a targeted retry.
Key Novelty
Verified Multi-Agent Orchestration (VMAO)
- Verification-Driven Replanning: Uses an independent LLM to evaluate if agent outputs satisfy the DAG plan, acting as a coordination signal decoupled from agent implementation
- DAG-Based Context Propagation: Decomposes queries into a dependency graph where upstream results are automatically passed to downstream agents, enabling efficient parallel execution
- Hierarchical Synthesis: Handles large result sets by summarizing within agent groups before creating the final answer, ensuring source attribution is preserved
Architecture
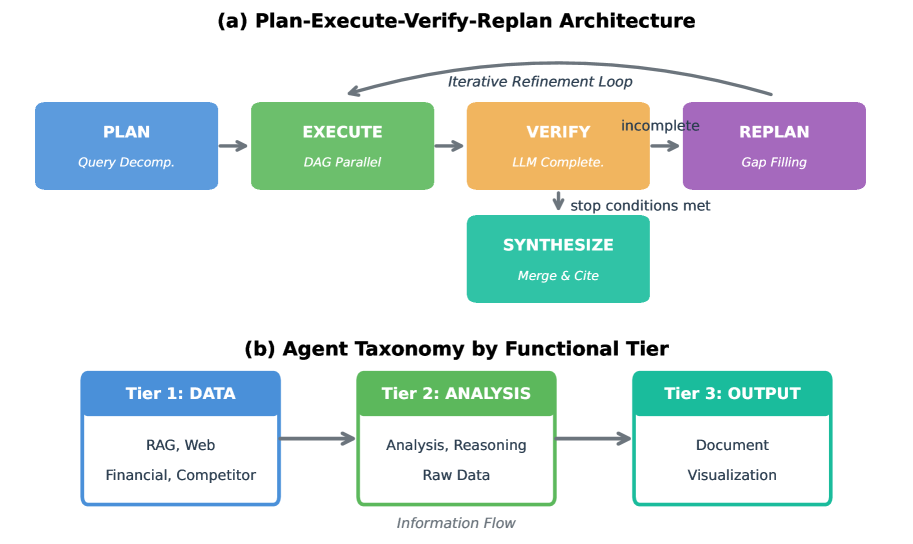
The five-phase VMAO workflow: Plan → Execute → Verify → Replan → Synthesize
Evaluation Highlights
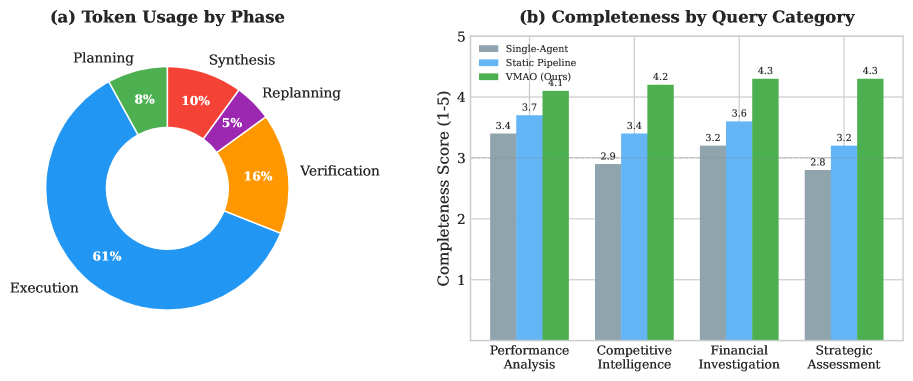
- +1.1 point improvement in Answer Completeness (4.2 vs 3.1 on 1-5 scale) compared to Single-Agent baseline on market research queries
- +1.5 point improvement in Source Quality (4.1 vs 2.6 on 1-5 scale), indicating significantly better citation and traceability
- +53% improvement in completeness specifically for Strategic Assessment queries, which require synthesizing information across multiple dimensions
Breakthrough Assessment
7/10
Strong engineering framework addressing the critical reliability gap in multi-agent systems via explicit verification. While methodologically straightforward, the implementation and specific application to complex research demonstrate significant practical value.