📝 Paper Summary
Video-LLM Hallucination Benchmarking
Factuality and Faithfulness Evaluation
INFACT is a diagnostic benchmark that evaluates Video-LLM reliability by subjecting models to controlled visual degradations, evidence corruptions, and temporal interventions to measure stability and grounding beyond clean accuracy.
Core Problem
Existing Video-LLM benchmarks focus primarily on clean-setting accuracy and video-verifiable faithfulness, neglecting factuality errors (contradicting world knowledge) and shortcut learning where models ignore video evidence.
Why it matters:
- High accuracy in clean settings often masks fragility; models may rely on language priors rather than actual video understanding
- Factuality hallucinations (e.g., misidentifying historical events or physical laws) are under-explored compared to visual inconsistencies
- Current benchmarks lack controlled perturbation protocols to distinguish true robust understanding from lucky guesses or static cue exploitation
Concrete Example:
A Video-LLM might correctly answer a question about a procedure in a clean video but fail when subtitles are maliciously altered (e.g., subtitles say 'closing door' while video shows 'opening'), or persist in its prediction even when the video frames are shuffled, proving it wasn't actually tracking the temporal order.
Key Novelty
Diagnostic Benchmark with Induced Hallucination Modes
- Introduces four evaluation modes: Base (clean), Visual Degradation (noise/blur), Evidence Corruption (misleading subtitles/adversarial noise), and Temporal Intervention (shuffling/reversal)
- Distinguishes between Faithfulness (video-conflict) and Factuality (world-knowledge-conflict) with a fine-grained taxonomy covering static entities, dynamics, and external knowledge domains
- Proposes specific reliability metrics: Resist Rate (RR) for stability under noise, and Temporal Sensitivity Score (TSS) to measure if models actually react to destroyed temporal logic
Architecture
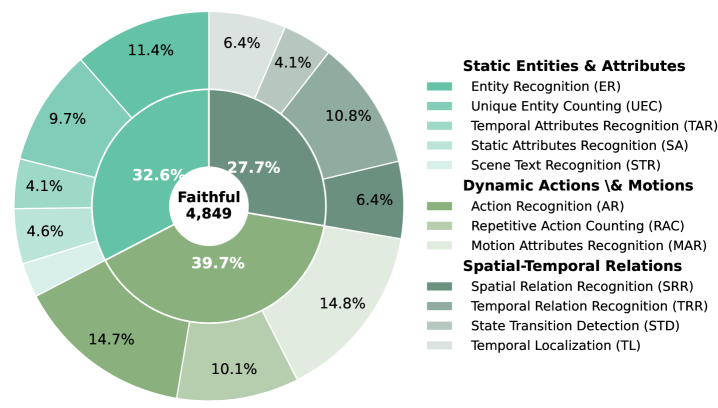
The hierarchical taxonomy of the INFACT benchmark
Evaluation Highlights
- Many open-source baselines exhibit near-zero Temporal Sensitivity Score (TSS) on factuality questions, indicating they ignore temporal order entirely
- Evidence corruption (e.g., misleading subtitles) degrades model reliability significantly more than visual degradation (e.g., blur/noise)
- Temporal intervention causes the largest performance degradation, revealing that high base accuracy often relies on static cues rather than temporal understanding
Breakthrough Assessment
8/10
Significant contribution by formalizing 'induced' hallucination modes and explicitly separating factuality from faithfulness. The finding that models possess near-zero temporal sensitivity for factuality is a strong diagnostic insight.