📝 Paper Summary
Generative Recommendation
Model Quantization
Inference Optimization
OneRec-V2's LLM-like numerical stability enables FP8 quantization and optimized inference infrastructure to nearly double throughput and halve latency without degrading recommendation quality.
Core Problem
Reliably applying low-precision quantization to industrial recommender systems is difficult because traditional models exhibit high-variance weights and memory-bound workloads that limit hardware utilization.
Why it matters:
- Traditional rankers are sensitive to quantization noise due to extreme outlier values, making low-precision inference risky
- Recommendation workloads are often memory-bound, meaning faster low-precision compute units (like Tensor Cores) often sit idle, yielding minimal speedups
- Industrial scale requires maximizing throughput per GPU to control serving costs while maintaining strict latency SLAs
Concrete Example:
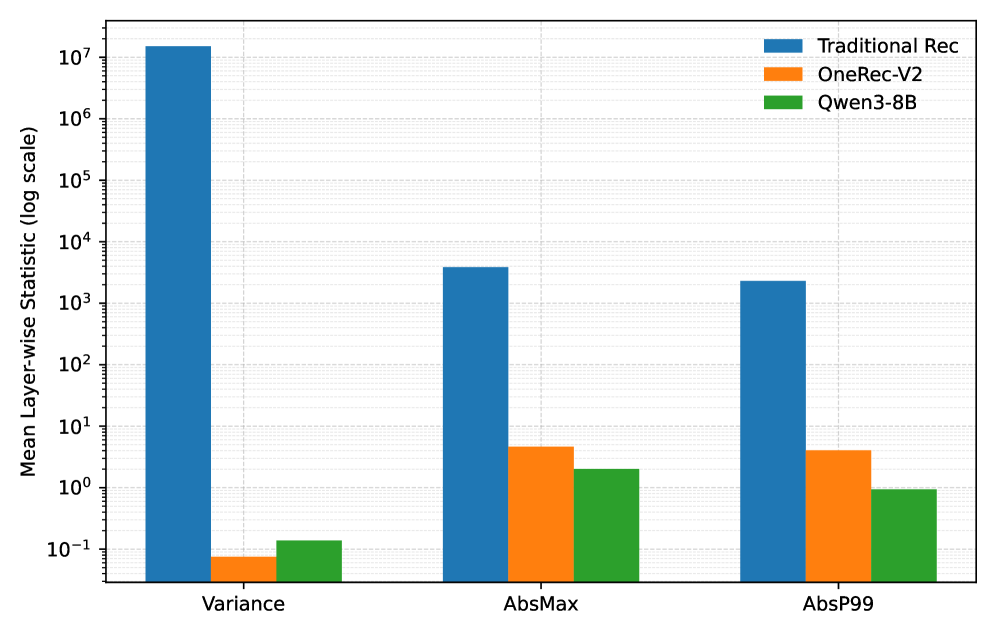
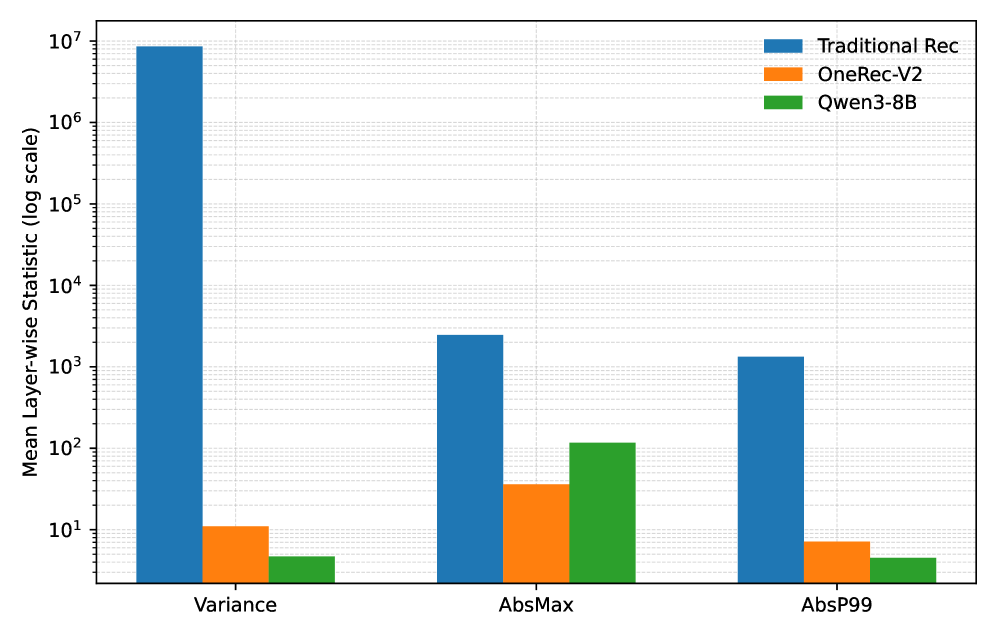
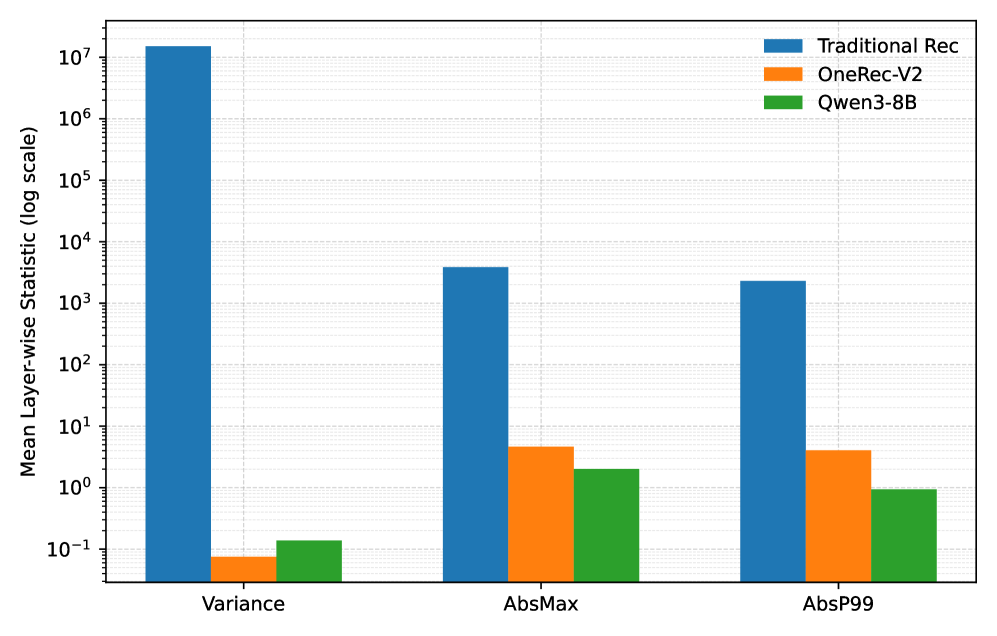
A traditional ranking model might have weight variances around 10^7 and absolute maximums over 1000, causing severe errors when rounded to FP8. In contrast, OneRec-V2 weights have variance < 0.1, similar to LLMs like Qwen3-8B.
Key Novelty
FP8 Inference for Generative Recommendation
- Empirically establishes that generative recommenders (OneRec-V2) have 'behaved' numerical statistics (low variance/magnitude) resembling LLMs, unlike chaotic traditional rankers
- Implements a specialized FP8 post-training quantization framework using block-wise scaling for MoE and dynamic scaling for activations to preserve accuracy
- Integrates quantization with a custom inference stack (RecoGEM) that fuses operators to shift the workload from memory-bound to compute-bound
Architecture
Comparison of standard FP16 Matrix Multiplication vs. the proposed FP8 Quantized Matrix Multiplication data flow.
Evaluation Highlights
- 49% reduction in end-to-end inference latency (139ms → 70ms) compared to FP16 baseline
- 92% increase in throughput (205 → 394 queries/sec) on production workloads
- Zero degradation in core metrics confirmed via extensive online A/B testing
Breakthrough Assessment
8/10
Significant industrial contribution proving generative recommenders bridge the gap to LLM-style efficiency optimizations. Strong results (2x throughput) on production-scale models.