📝 Paper Summary
Agentic AI
Tool Learning
Long-context reasoning
Tool-DC improves LLM tool-calling by splitting candidate tools into smaller groups for parallel inference, verifying results against schema constraints, and aggregating valid outputs for a final refined decision.
Core Problem
LLMs struggle to select correct tools from massive, noisy candidate lists because long contexts dilute reasoning signals and semantically similar tools cause confusion.
Why it matters:
- Current methods rely on retrievers; if the retriever misses the 'golden' tool, the LLM fails immediately
- Scaling candidate tools (e.g., from <10 to 20) causes significant performance degradation in existing models due to context length and noise
- Existing error-checking methods rely on rigid, manually defined checklists that lack flexibility
Concrete Example:
When the number of candidate tools scales from <10 to 20, the performance of standard models drops significantly (e.g., Qwen2.5-1.5B drops by over 25 points) because the model cannot effectively filter irrelevant tools or distinguish between tools with similar semantics but different arguments.
Key Novelty
Divide-and-Conquer with Try-Check-Retry
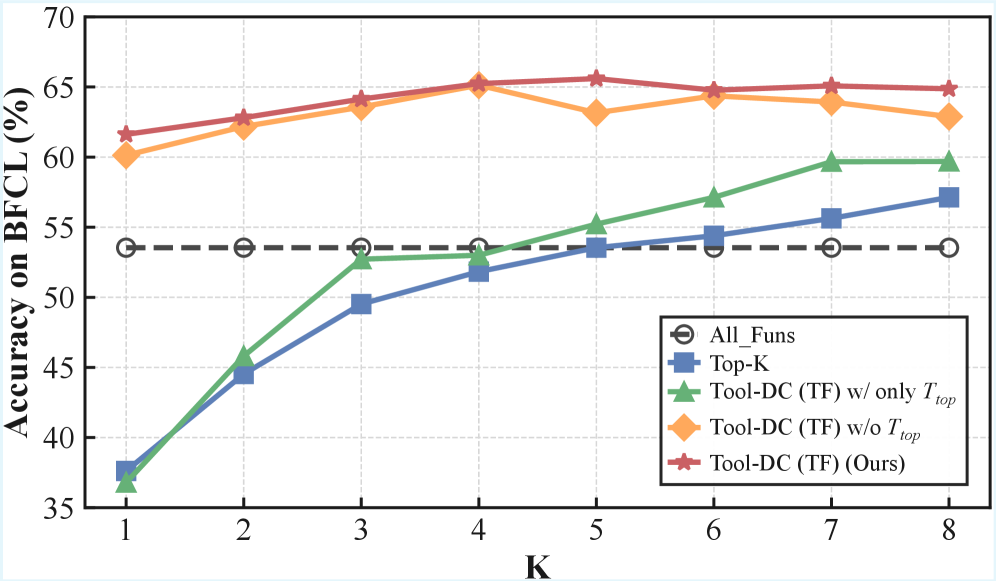
- Decomposes the search space into smaller 'anchor groups' (Try) to reduce reasoning difficulty and allow parallel processing
- Filters hallucinations using a rule-based validator (Check) that enforces strict schema compliance (function names, argument keys, data types)
- Aggregates only the validated candidates for a final, self-reflected decision (Retry), effectively removing noise before the final generation
Architecture
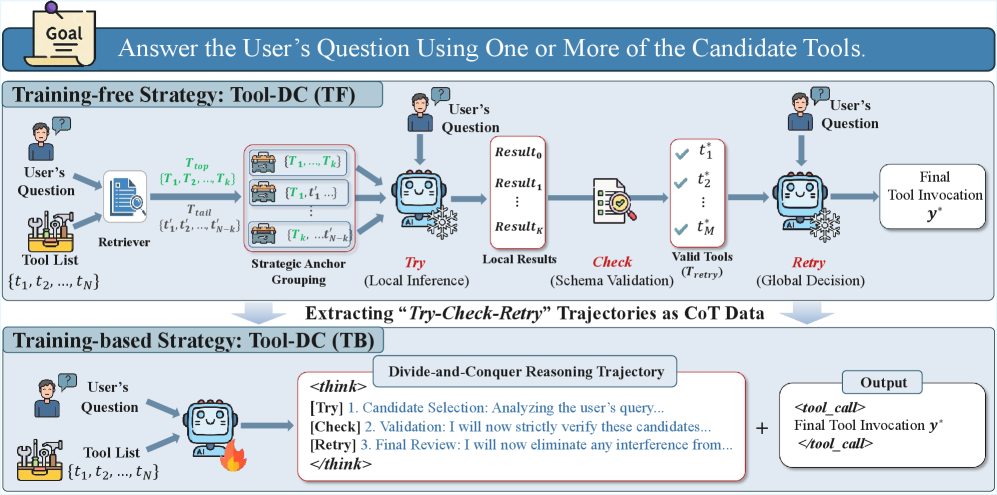
The overall framework of Tool-DC showing the two variants: Training-Free (TF) and Training-Based (TB). It depicts the flow from input query to final tool call.
Evaluation Highlights
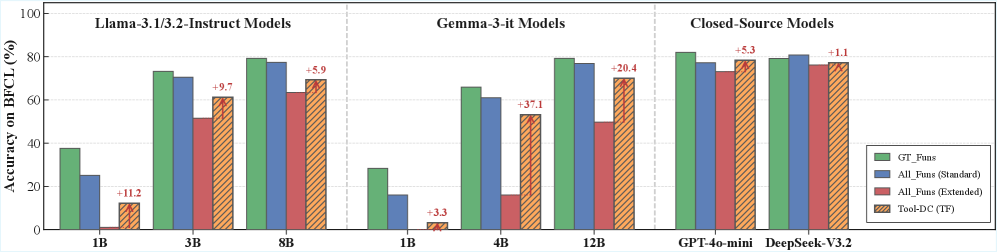
- Tool-DC (TF) achieves +25.10% average gain over the 'All Functions' baseline on the extended setting (20 candidate tools) using Qwen2.5-1.5B
- Tool-DC (TB) enables Qwen2.5-7B-Instruct to achieve an 83.16% overall score on the BFCL benchmark, outperforming proprietary models like OpenAI o3 and Claude-Haiku-4.5
- In the standard setting, Tool-DC (TF) improves Qwen2.5-1.5B performance by +4.61% compared to using all functions
Breakthrough Assessment
8/10
Significant performance jumps on noisy, long-context settings and impressive distillation results where a 7B model beats proprietary giants. The method is logically sound and addresses a key bottleneck in agentic systems.