📝 Paper Summary
KV Cache Compression
Reasoning Models (Chain-of-Thought)
Inference Efficiency
LongFlow compresses the KV cache during long reasoning generation by identifying important tokens using only the current query's attention contribution, fused into a single efficient kernel.
Core Problem
Reasoning models generate extremely long output sequences (Chain-of-Thought), causing KV caches to explode in size and create memory/bandwidth bottlenecks.
Why it matters:
- Existing compression methods target long-input scenarios (prefill compression) and fail during the long-output decoding phase characteristic of reasoning models
- Prior importance estimation metrics require expensive 'look-back' computations or auxiliary storage, which adds prohibitive overhead when re-evaluated at every generation step
- Standard attention kernels (like FlashAttention) are incompatible with dynamic compression logic, forcing costly data movement between memory levels
Concrete Example:
When a model like DeepSeek-R1 generates a 10,000-token math proof, the KV cache grows linearly. A standard compression method like SnapKV only compresses the initial prompt, leaving thousands of generated intermediate tokens in memory, eventually hitting OOM or slowing generation to a crawl.
Key Novelty
Zero-History, Zero-Cost Importance Estimation with Fused Kernel
- Estimates token importance using only the current query and the intermediate contribution vector from the standard attention pass, avoiding any need for historical query storage or separate importance computations
- Integrates the compression logic (scoring and eviction) directly into a custom Triton kernel that fuses it with FlashAttention, performing eviction 'for free' during the attention calculation
Architecture
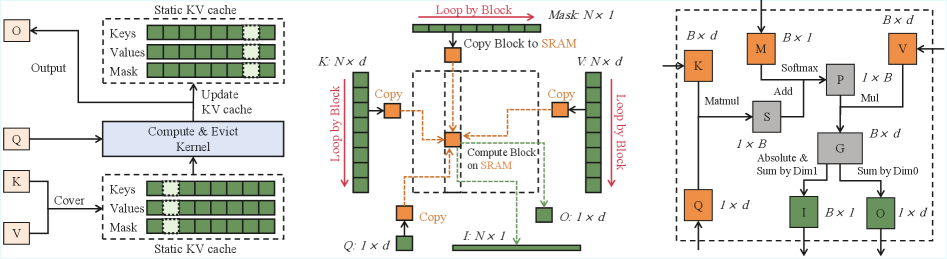
The data flow and computation logic of the LongFlow system, specifically the fused kernel operation.
Evaluation Highlights
- Achieves up to 11.8x throughput improvement compared to full cache baselines while maintaining model accuracy
- Reduces KV cache size by 80% with minimal degradation on reasoning tasks
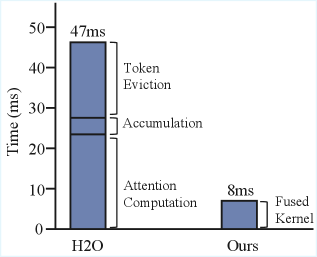
- Lowers attention latency from 47ms to 8ms using the custom fused kernel compared to standard implementations
Breakthrough Assessment
8/10
Addresses a critical, specific bottleneck for the new wave of reasoning models (long output vs long input). The theoretical derivation for the simplified metric and the custom kernel implementation make it highly practical.