📊 Experiments & Results
Evaluation Setup
Comprehensive multilingual suite including translation, open-ended generation, and safety
Benchmarks:
- WMT24++ (Machine Translation)
- mDolly (Open-ended generation / Instruction Following)
- MultiJail (Multilingual Safety)
Metrics:
- ChrF
- Safety Rate (%)
- Win Rate (implied for generation tasks)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparative performance on translation quality demonstrates Tiny Aya's advantage over similar-sized models. | ||||
| WMT24++ | Win Count (languages) | 9 | 46 | +37 |
| mDolly | Score | Not reported in the paper | Not reported in the paper | +5 |
| Region-specialized models show significant gains over the global baseline in their respective target regions. | ||||
| WMT24++ (South Asia) | ChrF | Not reported in the paper | Not reported in the paper | +5.5 |
| WMT24++ (Africa) | ChrF | Not reported in the paper | Not reported in the paper | +1.7 |
| Safety evaluation shows Tiny Aya achieves high safety rates while maintaining consistency across languages. | ||||
| MultiJail | Mean Safe Response Rate (%) | Not reported in the paper | 91.1 | Not reported in the paper |
Experiment Figures
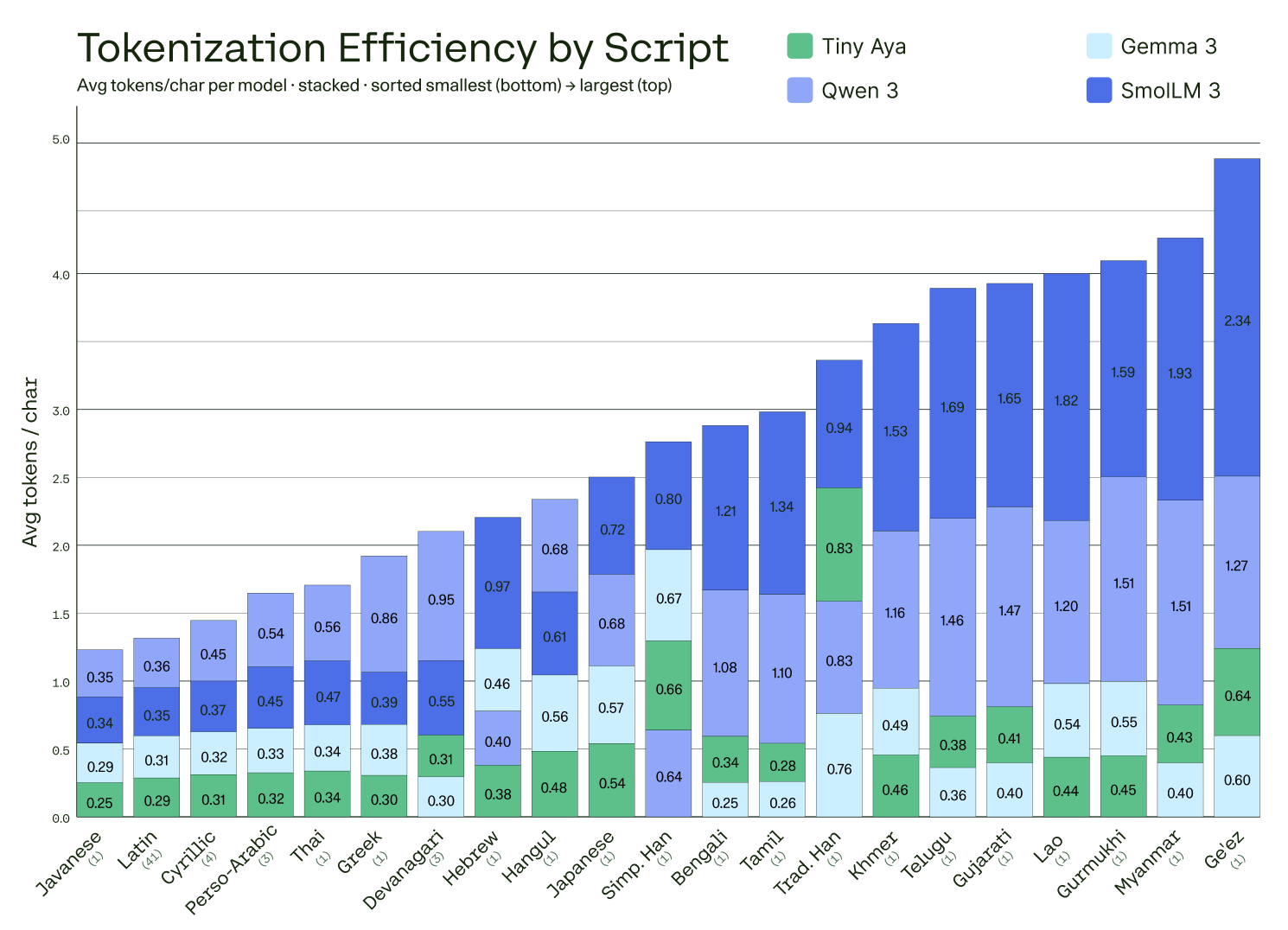
Comparison of tokenizer efficiency (average tokens per character) by script for Tiny Aya vs. Gemma 3-4B, Qwen 3-4B, and SmolLM 3-3B
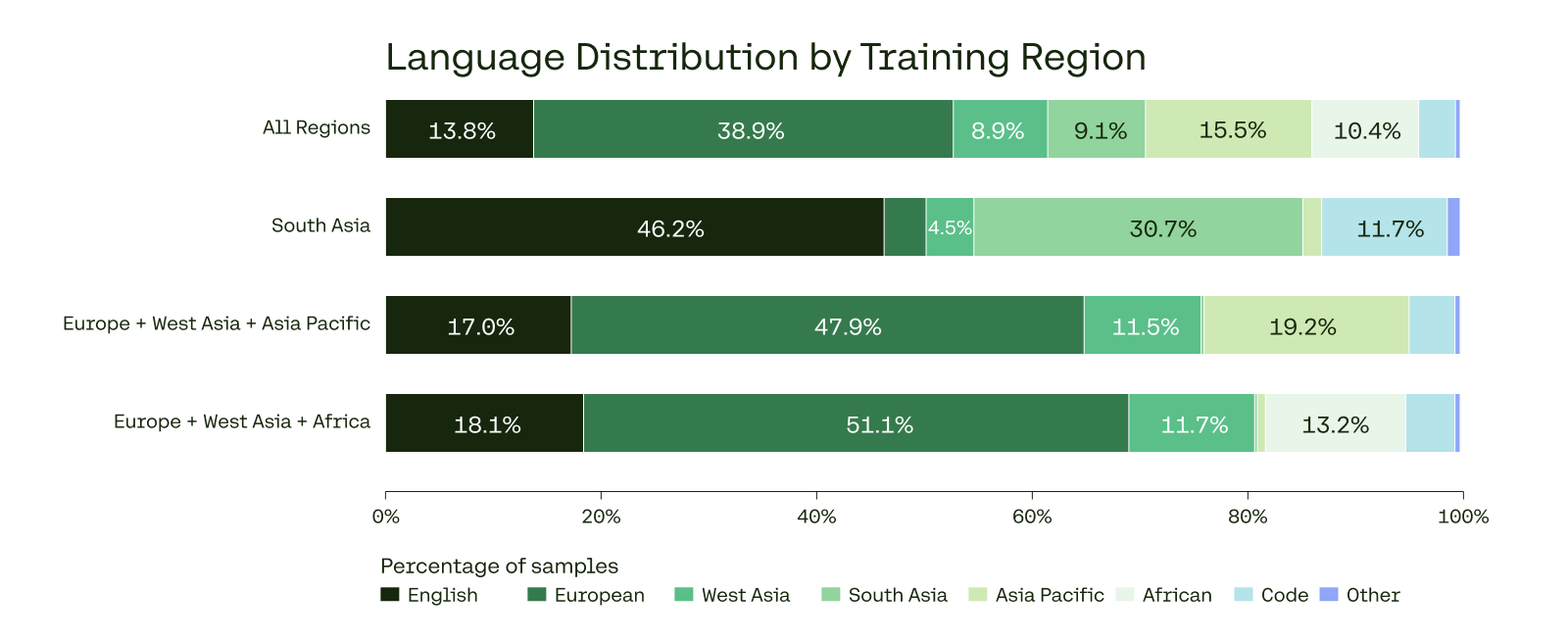
Proportion of data from each region (Africa, South Asia, Europe, etc.) for each of the region-specialized clusters
Main Takeaways
- Balanced data curation combined with specialized tokenization significantly improves performance on low-resource languages without increasing model size
- Region-specialized post-training (Earth, Fire, Water) yields clear gains (e.g., +5.5 ChrF in South Asia) compared to a single monolithic global model
- The 'Fusion-of-NN' synthetic data pipeline effectively boosts quality by leveraging stronger teacher models to correct and refine multilingual data
- Safety performance is robust (91.1%) and remarkably consistent across languages, reducing the typical safety gap between English and other languages