📊 Experiments & Results
Evaluation Setup
Pretraining Language Models on FineWeb-Edu
Benchmarks:
- Validation Cross-Entropy (CE) Loss (Language Modeling)
- CORE Benchmark (Common sense reasoning and language understanding)
Metrics:
- Cross-Entropy Loss
- CORE Score
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main comparison results showing ET superiority over Token Choice (TC) baselines and parity with large-batch Expert Choice (EC) on d12 (575M params) and d20 (2.4B params) models. | ||||
| d12 Model (Validation CE) | Cross-Entropy Loss | 2.891 | 2.844 | -0.047 |
| d12 Model (CORE Eval) | CORE Score | 17.99 | 19.88 | +1.89 |
| d20 Model (Validation CE) | Cross-Entropy Loss | 2.710 | 2.643 | -0.067 |
| d20 Model (CORE Eval) | CORE Score | 22.65 | 25.48 | +2.83 |
| Batch size scaling analysis for Expert Choice (EC) showing that small-batch EC degrades performance, validating the need for ET's 'infinite-batch' approximation. | ||||
| d12 Model (CORE Eval) | CORE Score | 17.91 | 19.88 | +1.97 |
Experiment Figures
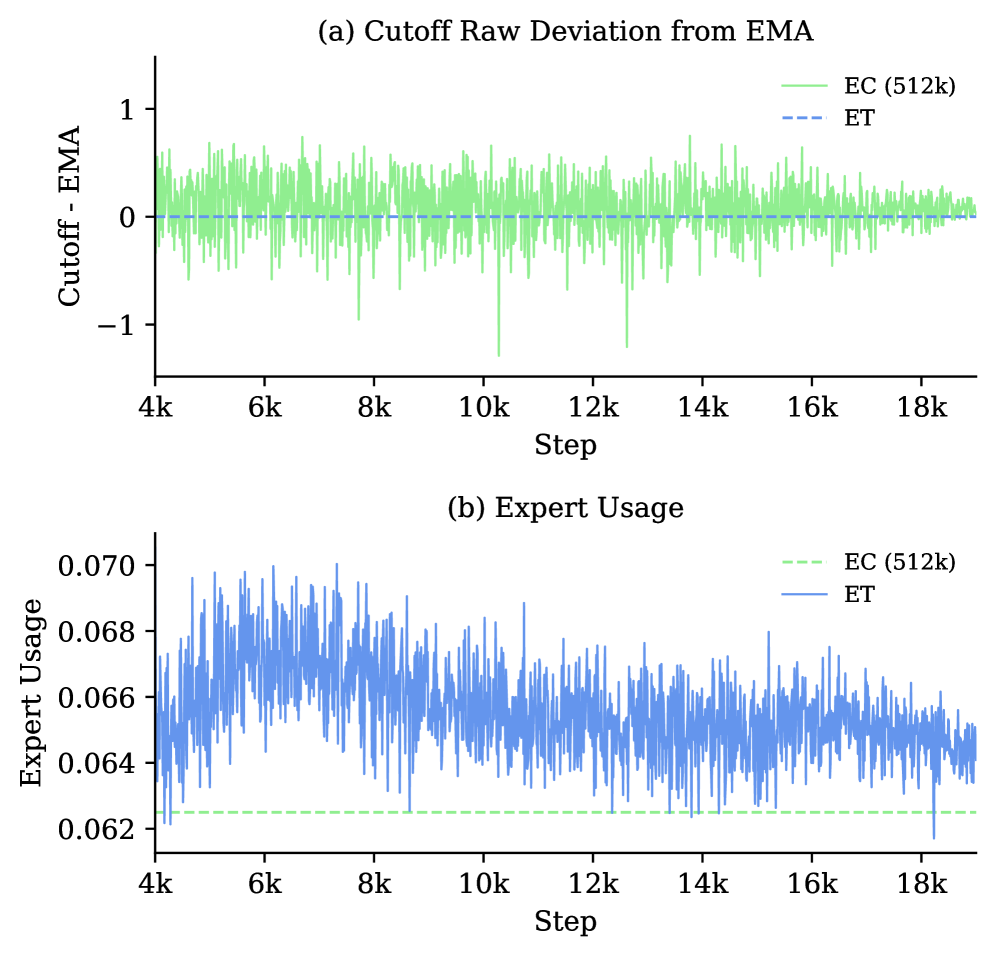
Signed deviation between EC's per-batch cutoff and the EMA cutoff used by ET.

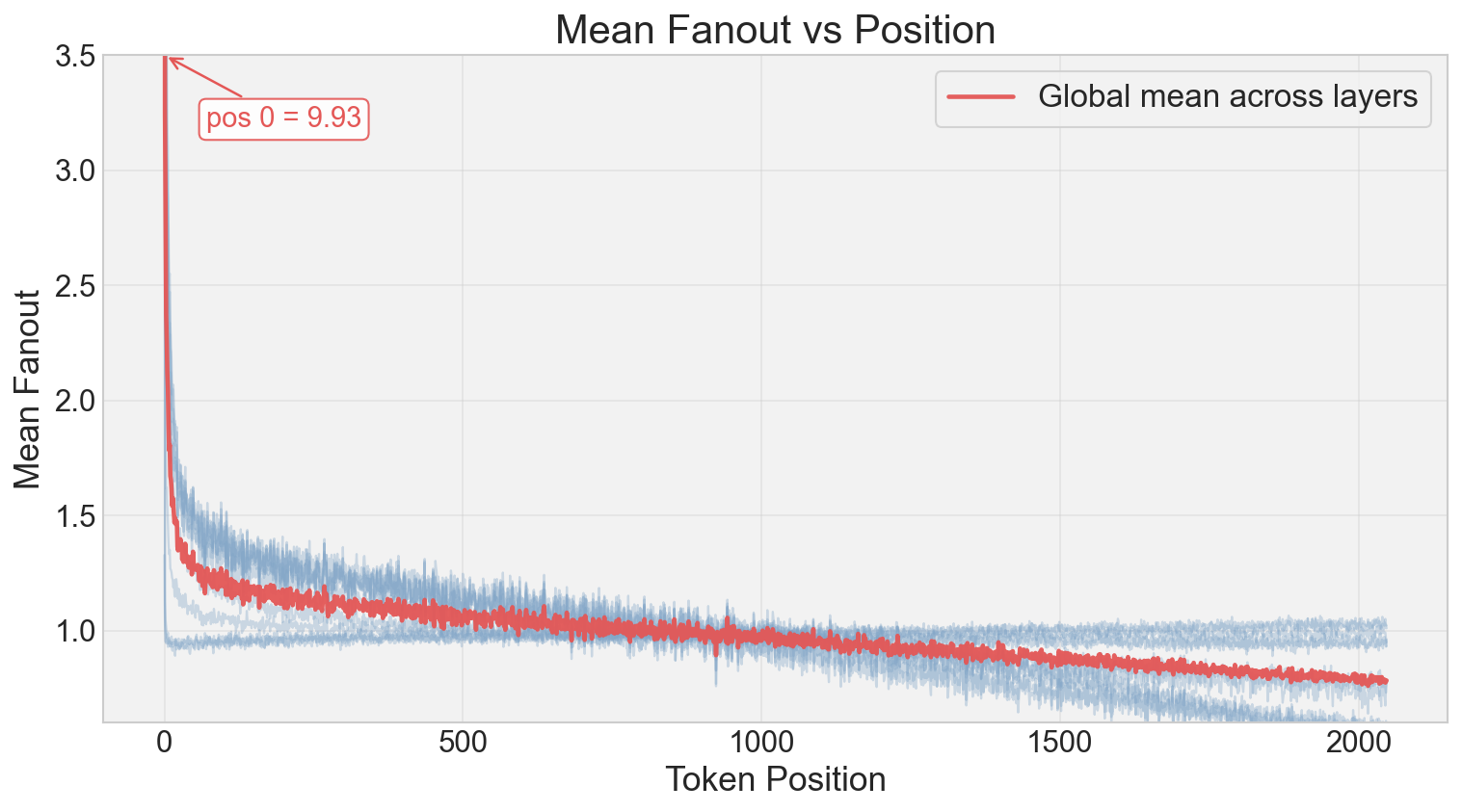
Fanout (experts selected per token) vs. Token Index and Loss.
Train vs Evaluation Loss gap for EC at different batch sizes vs ET.
Main Takeaways
- ET achieves near-perfect load balancing without auxiliary losses or strict constraints.
- ET outperforms Token Choice consistently and matches the performance of Expert Choice with very large batch sizes (512k), but without the inference-time causality violations.
- Expert Choice performance degrades significantly at small batch sizes (e.g., 2k), creating a train-inference mismatch that ET solves via stable global thresholds.
- ET allows for dynamic computation (variable experts per token) similar to EC, allocating more compute to 'harder' tokens (high loss) and early sequence positions.