📝 Paper Summary
LLM Inference Efficiency
Memory Management
DapQ compresses the Key-Value cache by constructing pseudo-queries with future positional encodings, leveraging the insight that query position determines attention patterns more than semantic content.
Core Problem
Existing KV cache compression methods rely on input-side observation windows (e.g., the last few prompt tokens) to estimate token importance, but these windows fail to reflect the actual queries that will occur during the decoding phase.
Why it matters:
- Misaligned observation windows cause models to discard critical information (like specific 'needles' in long contexts) needed for future generation, leading to hallucination or forgetting
- Ground-truth decoding queries are unavailable during the prefill stage, making it difficult to know *a priori* which cached tokens will be attended to
- Long-context inference suffers from massive memory footprints; accurate compression is essential to deploy LLMs on constrained hardware
Concrete Example:
In a 'Needle-in-a-Haystack' task where the answer relies on a sentence buried in the middle of a long document, standard methods like SnapKV calculate importance based only on the end of the prompt. Since the end of the prompt may not semantically relate to the buried needle, SnapKV evicts the needle. DapQ simulates the *future* position of the answer generation, correctly identifying and retaining the needle.
Key Novelty
Decoding-aligned KV cache compression via position-aware pseudo queries (DapQ)
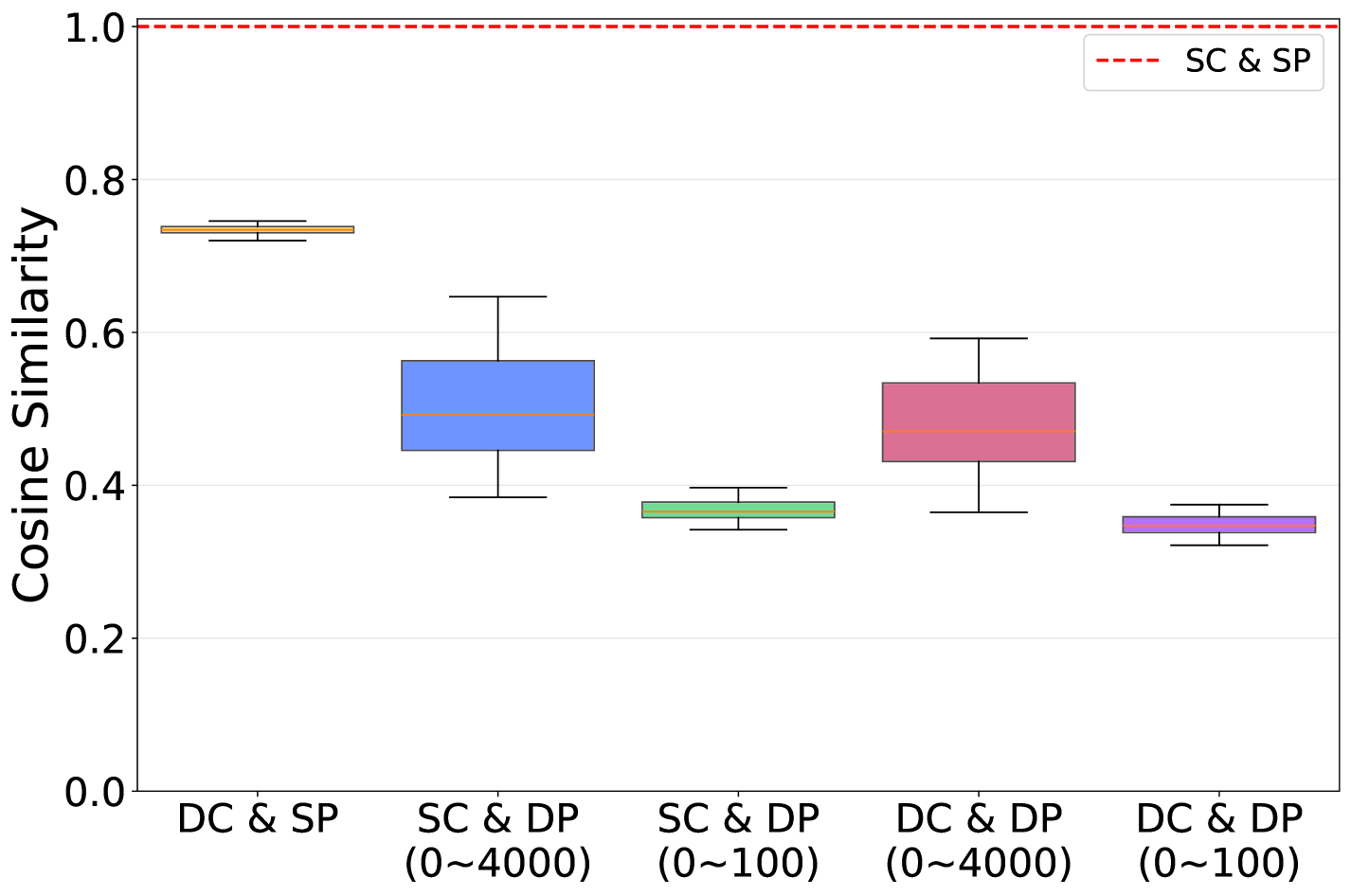
- Discovers that for attention scoring, the positional encoding of a query vector is far more influential than its semantic content (Where > What)
- Constructs 'Pseudo Queries' by appending dummy tokens (copies of prefix/suffix) to the input and assigning them *future* positional IDs corresponding to the decoding steps
- Uses these position-aware pseudo queries to probe the Key-Value cache during prefill, retaining only tokens that have high attention scores with the simulated future positions
Architecture
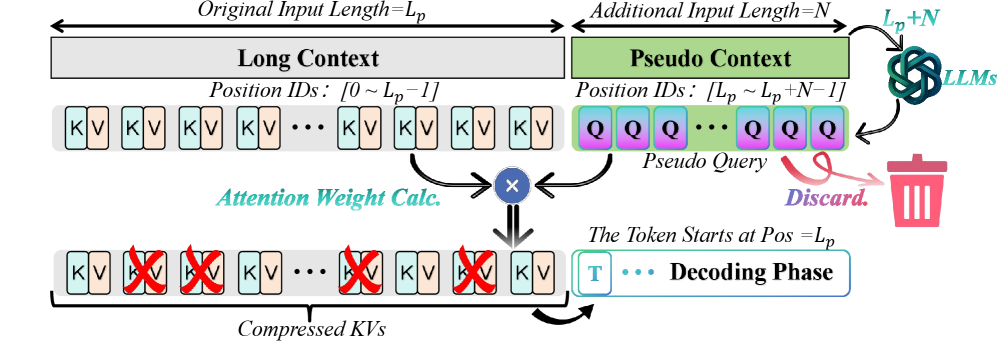
Overview of the DapQ framework compared to standard methods. It illustrates the prefill stage where pseudo queries are appended.
Evaluation Highlights
- Achieves 99.5% accuracy on Needle-in-a-Haystack (NIAH) with LLaMA3-8B under a strict 3% KV cache budget (256 tokens), recovering nearly lossless performance
- +6.75% accuracy improvement over SnapKV on the 'Hard' category of LongBenchV2 using LLaMA3-8B with a budget of 64 tokens
- Outperforms SnapKV by 58.2 points (59.6% vs 1.4%) on the Ruler benchmark's S-NIAH-3 task with a budget of 512 tokens
Breakthrough Assessment
8/10
Offers a highly effective, theoretically grounded solution (position dominance) to the alignment problem in KV compression. The gains on difficult retrieval tasks (NIAH, Ruler) are drastic compared to baselines.