📝 Paper Summary
Visual Question Answering (VQA)
Chart Understanding
VisDoT improves chart reasoning by training LVLMs on cognitive perceptual tasks and using a prompting strategy that separates visual element identification from logical reasoning.
Core Problem
Large vision-language models (LVLMs) struggle to align visual primitives (like position or length) with semantic concepts in charts, leading to failure in complex reasoning tasks.
Why it matters:
- Models fail to reliably detect visual primitives when users don't explicitly name identifiers (e.g., legend labels).
- Standard Chain-of-Thought (CoT) works for text but lacks grounding for visual attributes like color and spatial coordinates.
- Instruction tuning often focuses on simple keyword-value mappings rather than the high-level perceptual alignment needed for multi-object comparison.
Concrete Example:
In a chart query, a user might ask about a data trend without naming the axis labels. Current LVLMs fail to 'ground' the visual bars to their values before reasoning, resulting in hallucinated statistics.
Key Novelty
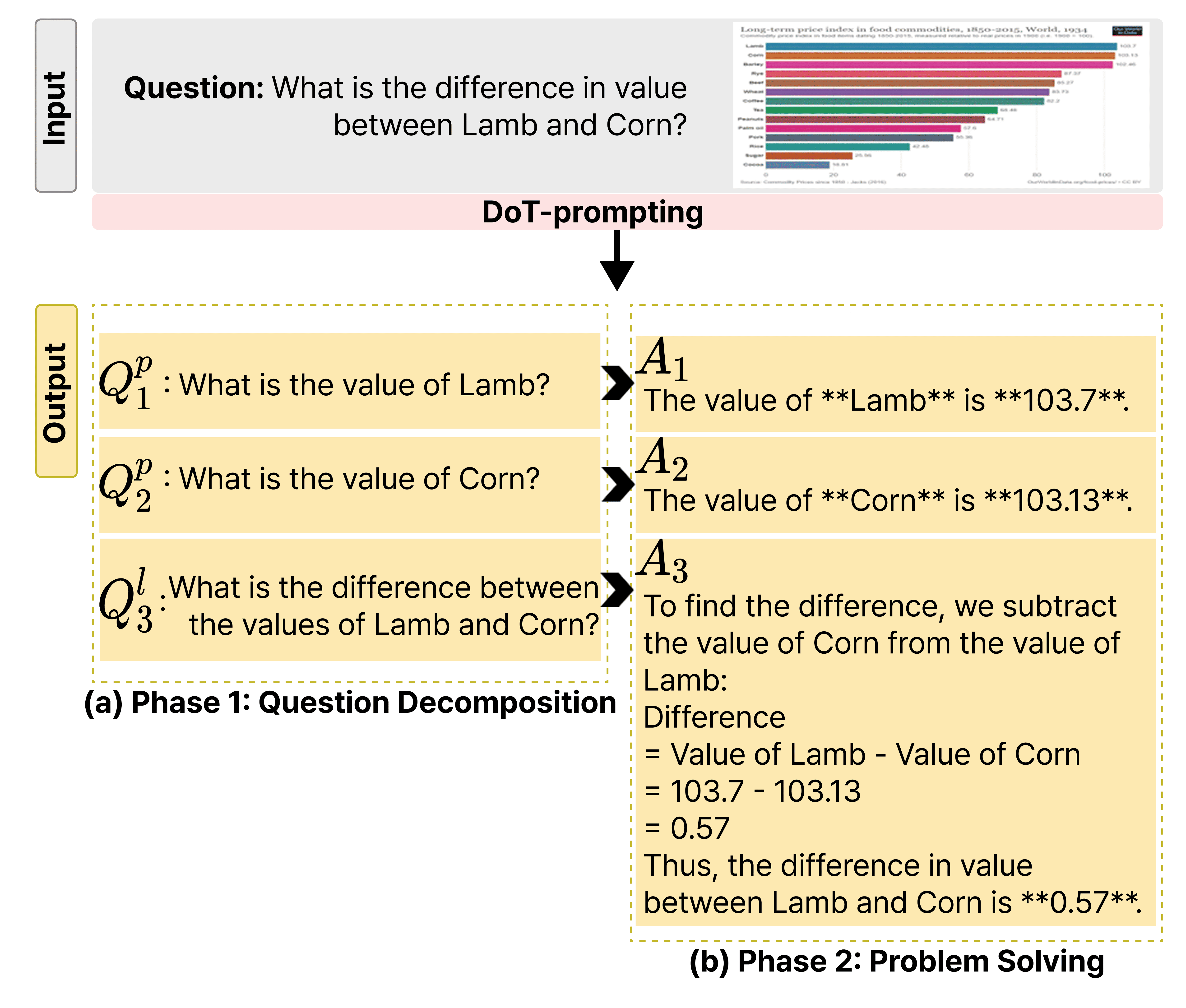
Human-Like Interpretation Grounding & Decomposition of Thought (DoT)
- Formalizes four perceptual tasks (Position, Length, Pattern, Extract) based on Cleveland & McGill's graphical perception theory to align model attention with human visual processing.
- Introduces Decomposition-of-Thought (DoT), a prompting strategy that explicitly splits a query into 'perception' sub-questions (finding elements) and 'logic' sub-questions (reasoning about them).
- Treats VQA as a sequential process where perception questions must be answered to ground the context before logical operations are performed.
Architecture
Overview of the VisDoT framework, illustrating both the data generation pipeline (Perception-Following Question Generation) and the inference pipeline (Decomposition-of-Thought).
Evaluation Highlights
- +11.2% improvement on ChartQA benchmark using InternVL fine-tuned with VisDoT.
- +33.2% improvement on the newly introduced VisDoTQA benchmark compared to baselines.
- Surpasses GPT-4o on the challenging ChartQAPro benchmark.
- Increases performance by +2.2% absolute on MMMU (open-domain VQA) over an identical Chain-of-Thought backbone.
Breakthrough Assessment
8/10
Strong improvements on specialized chart benchmarks and valid generalization to open-domain VQA. The integration of cognitive psychology (graphical perception) into the prompting/training pipeline is a significant methodological contribution.