📝 Paper Summary
Offline Reinforcement Learning
Multi-Agent Reinforcement Learning (MARL)
Transformer Architectures
STAIRS-Former improves offline multi-task multi-agent RL by employing a recursive transformer with hierarchical history tracking and token dropout to better capture agent interactions and long-term dependencies.
Core Problem
Existing offline MARL methods use transformers (like UPDeT) with shallow attention and simple history tokens, failing to capture complex inter-agent relations and long-term dependencies in partially observable settings.
Why it matters:
- Real-world multi-agent systems (drones, vehicles) must adapt to varying numbers of agents and unseen scenarios, which current methods struggle to handle robustly
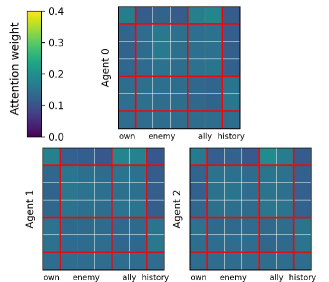
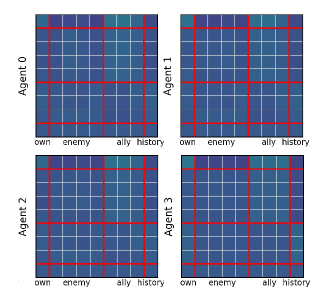
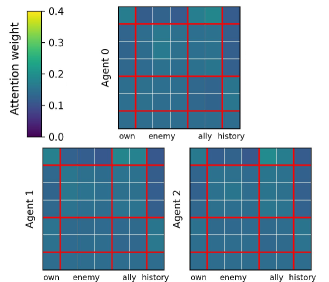
- Shallow transformers result in uniform attention maps that miss critical entities, limiting the policy's ability to prioritize relevant information
- Simple RNN-style history tokens in prior work cannot effectively store long-horizon information required for decision-making under partial observability
Concrete Example:
In the SMAC 'Marine-Easy' task, prior methods like HiSSD produce attention maps that are distributed nearly uniformly across all tokens, failing to focus on specific enemies or allies. Additionally, their history tokens are not heavily attended to, indicating a failure to utilize past context.
Key Novelty
Spatio-Temporal Attention with Interleaved Recursive Structure (STAIRS)
- Uses a recursive transformer (Spatial-Former) that iteratively refines latent representations to deepen reasoning about relationships between agents and entities
- Splits the Feed-Forward Networks (FFNs) into two separate paths—one for spatial entities and one for history—to prevent temporal context from blurring spatial features
- Implements a hierarchical history mechanism with a fast-updating step-token and a slow-updating GRU token to capture both immediate and long-term context
Architecture
The architecture of STAIRS-Former, showing the decomposition of observations, the Spatial Recursive Module, and the Temporal Module
Breakthrough Assessment
8/10
Proposes a structurally novel transformer specifically tailored for the partial observability and varying entity counts of MARL. The dual-path FFN and hierarchical history address specific weaknesses in prior UPDeT-based architectures.