📝 Paper Summary
Text-to-Video Generation
Video Understanding Benchmarks
OSCBench is a benchmark designed to evaluate whether text-to-video models correctly render object state changes (e.g., slicing a lemon) across regular, novel, and compositional scenarios.
Core Problem
Current text-to-video (T2V) models generate high-quality visuals but often fail to faithfully realize the consequences of actions, specifically the transformation of an object from an initial to a target state.
Why it matters:
- Existing benchmarks focus on physical plausibility or general alignment but overlook explicit Object State Change (OSC), which is critical for instructional video generation and embodied AI
- Models may produce realistic motion patterns while failing to render the actual state transition (e.g., an object appearing intact after a 'chopping' action)
- Correctly modeling OSC requires deep language-grounded reasoning to infer intended transformations, which current models struggle to generalize
Concrete Example:
When prompted with 'slicing a lemon', a model might generate a video of a knife moving near a lemon, but the lemon remains whole (incorrect state change) or transforms implausibly.
Key Novelty
OSCBench (Object State Change Benchmark)
- Constructs a dataset of instructional cooking scenarios abstracting actions and objects into categories to ensure diversity and avoid long-tail bias
- Organizes evaluation into three difficulty regimes: Regular (common pairs), Novel (uncommon but feasible pairs), and Compositional (sequences of actions) to test generalization
- Employs a Chain-of-Thought (CoT) evaluation strategy using Multimodal Large Language Models (MLLMs) to mimic fine-grained human reasoning about state evolution
Architecture
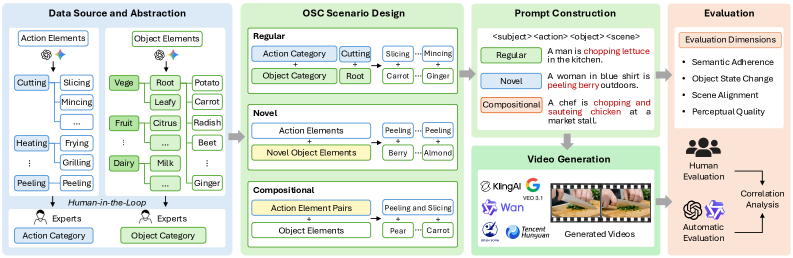
The construction pipeline of OSCBench, illustrating the abstraction of raw data into categories and the generation of diverse scenarios.
Evaluation Highlights
- Benchmark comprises 1,120 prompts across 140 distinct object-state scenarios
- Includes 20 'Novel' scenarios specifically designed to test generalization to uncommon action-object pairs (e.g., peeling berries)
- Evaluation covers 6 State-of-the-Art models including proprietary systems like Kling-2.5-Turbo and Veo-3.1-Fast
Breakthrough Assessment
7/10
Addresses a specific, high-value failure mode in T2V generation (state changes). The categorization into regular/novel/compositional is methodologically sound, though the paper is primarily a benchmark contribution rather than a modeling breakthrough.
