📝 Paper Summary
Data Selection for Pretraining
LLM Pretraining Efficiency
QuaDMix is a data selection framework that jointly optimizes quality and diversity by using a parameterized sampling function tuned via proxy models to predict downstream performance.
Core Problem
Existing data selection methods optimize quality and diversity separately (e.g., filtering then mixing), overlooking their inherent trade-off and interplay, which leads to suboptimal pretraining efficiency.
Why it matters:
- High-quality data is limited, and aggressive filtering can reduce diversity, hurting model generalization.
- Different quality criteria have biases that skew domain distributions, meaning optimal mixtures depend on the quality filters used.
- Current approaches rely on heuristics or manual tuning for mixing ratios, which is inefficient and scales poorly.
Concrete Example:
Choosing a strict quality filter (like educational value) might inadvertently filter out most 'Sports' or 'Entertainment' data, skewing the distribution. Independently optimizing for 'quality' (filtering) and then 'diversity' (mixing) fails to account for how the filter itself altered the domain composition.
Key Novelty
Unified Parameterized Sampling for Quality-Diversity Balance
- Defines a sampling function that assigns probabilities based on a weighted combination of multiple quality scores and domain labels, rather than hard filtering.
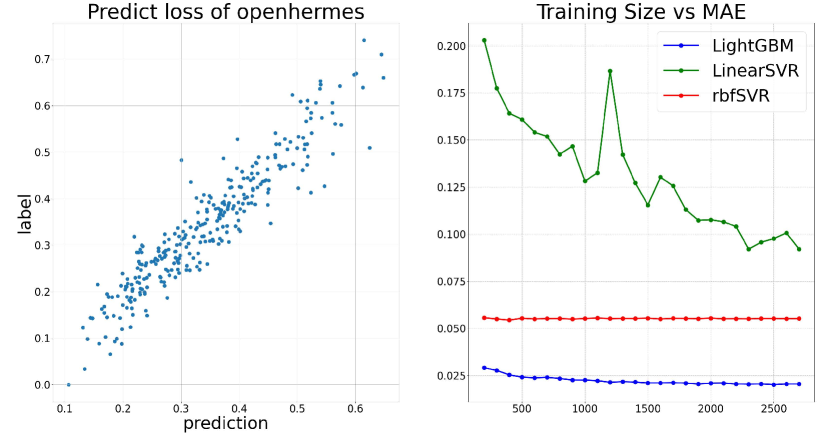
- Uses a two-step optimization: first training many small proxy models (1M parameters) to gather performance data, then training a regressor to predict the performance of unseen sampling parameters.
- Optimizes parameters specifically for target downstream tasks by using those tasks' training data as the validation set for the proxy models.
Architecture
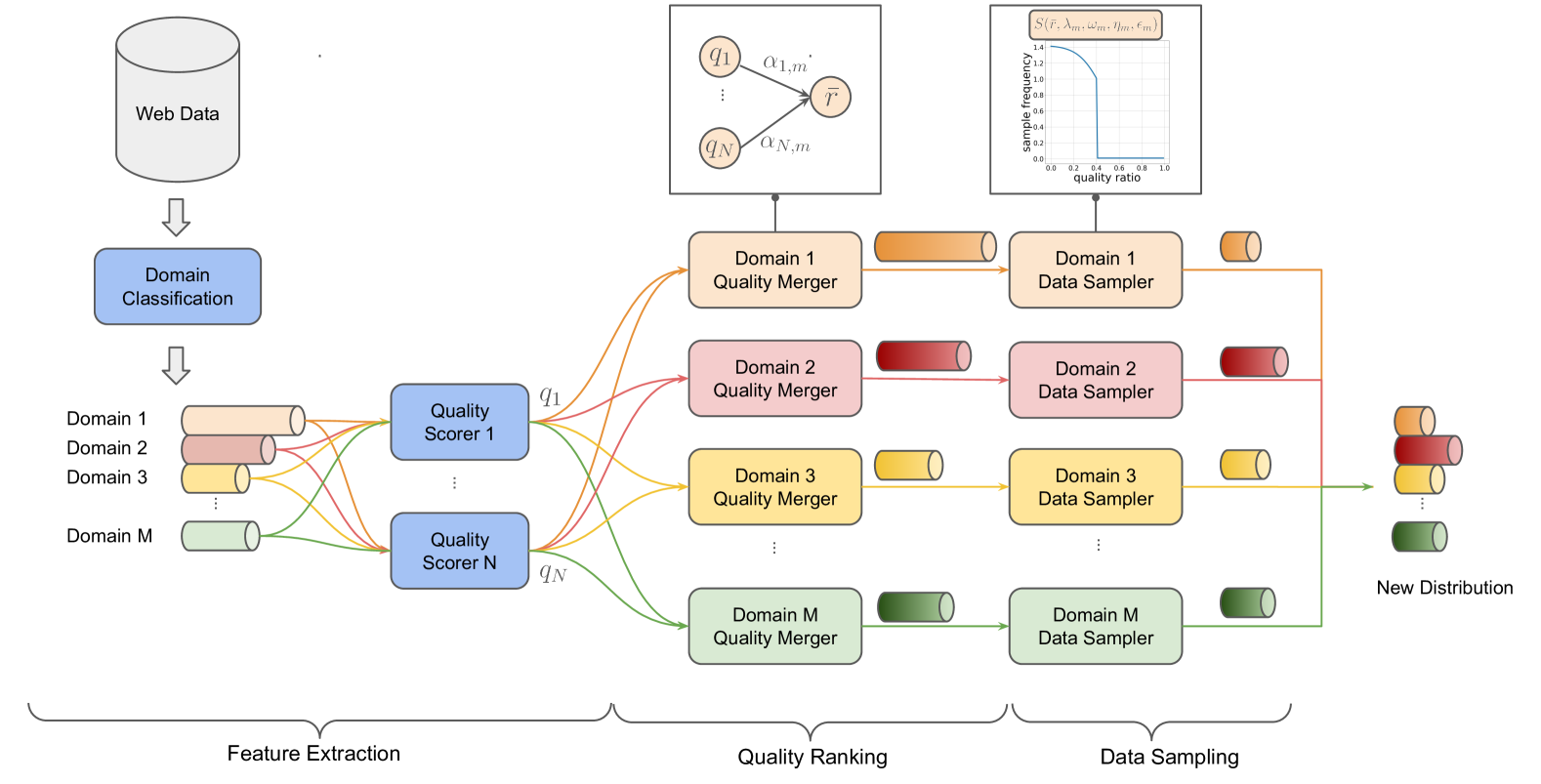
The QuaDMix pipeline: Feature Extraction -> Parameterized Sampling -> Proxy Model Training -> Regression -> Optimal Parameter Search -> Large Scale Training.
Evaluation Highlights
- Achieves an average performance improvement of 7.2% across multiple benchmarks (including MMLU, HellaSwag, ARC) compared to random selection.
- Outperforms independent strategies like RegMix (diversity only) and AskLLM/Fineweb-edu (quality only) on an aggregated benchmark of 9 tasks.
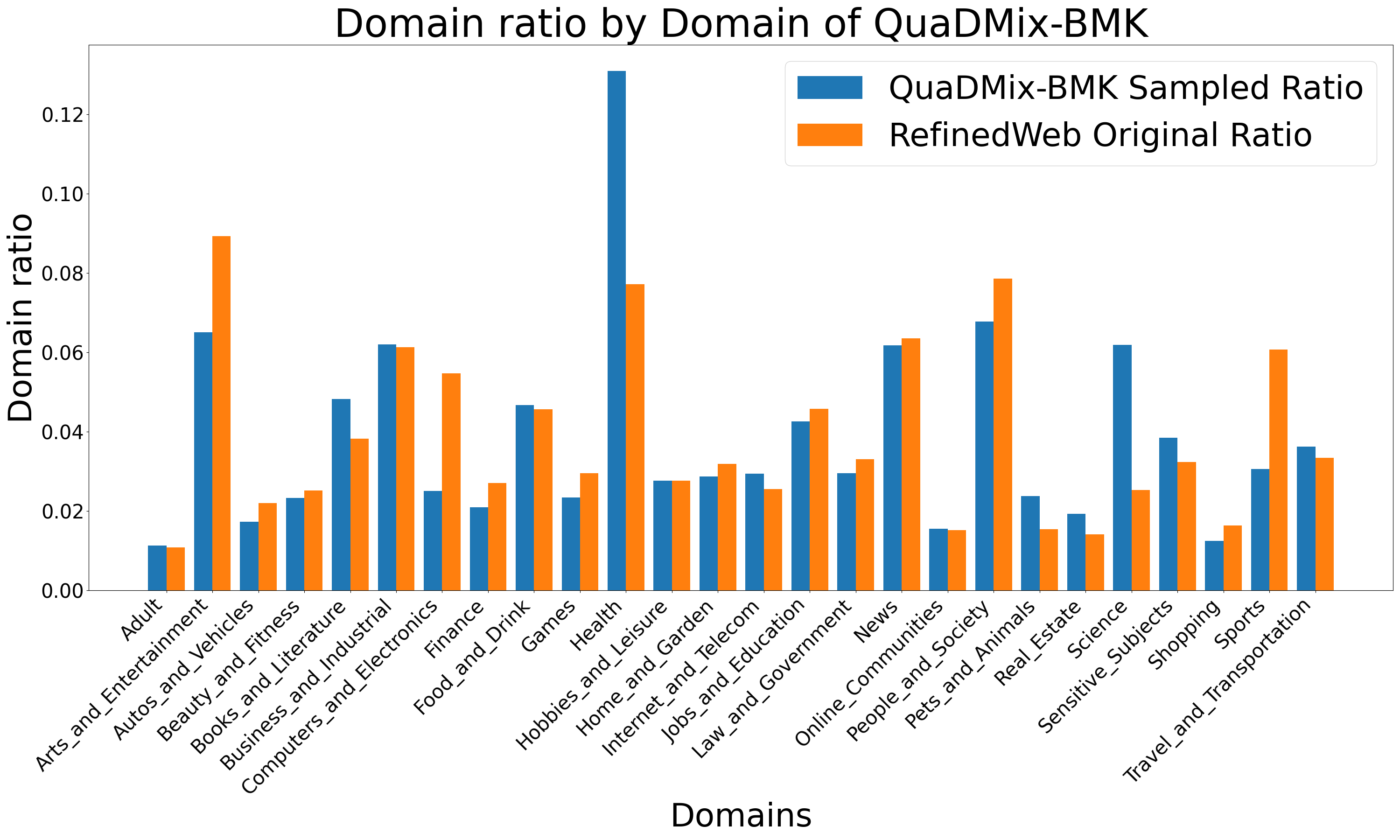
- Demonstrates that task-specific optimization (QuaDMix-BMK) further boosts performance by using downstream task data as the validation target.
Breakthrough Assessment
7/10
Solid contribution addressing the specific interaction between quality and diversity. The use of very small proxy models (1M params) to tune 530M models is efficient, though the scale of the final evaluation (530M) is relatively small compared to modern standards.