📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation on general language benchmarks and qualitative analysis of perplexity on future news
Benchmarks:
- HellaSwag (Commonsense reasoning)
- MMLU (Multitask academic knowledge)
- IFEval (Instruction following)
- Bloomberg News Headlines (Memorization/Perplexity probing) [New]
Metrics:
- Accuracy
- Perplexity
- Average Score
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
Training loss curves for the pretraining stage
Main Takeaways
- DatedGPT models achieve an average score of up to 42.7 across standard benchmarks, showing that strict temporal filtering does not destroy general language capabilities compared to similarly sized models.
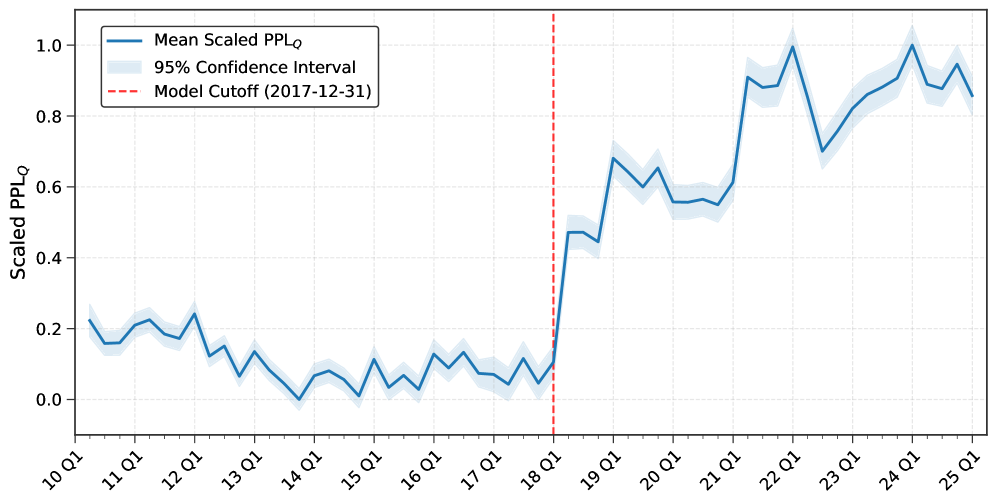
- Models demonstrate 'perplexity reversal': they show low perplexity (high familiarity) with data prior to their cutoff and high perplexity (surprise) for data after their cutoff, confirming the effectiveness of the lookahead bias prevention.
- Performance is consistent across different cutoff years (40.1 to 42.7 average), suggesting that the volume of data per year (~100B tokens) is sufficient for stable model performance regardless of the specific year.
- The instruction-tuning stage uses a teacher-student approach (Llama-3.3-70B teacher) to create safe, date-aware instruction sets, ensuring the model doesn't learn future knowledge during fine-tuning.