📝 Paper Summary
Model Compression
Large Language Model Inference Efficiency
EntroDrop prunes redundant transformer blocks by measuring entropy increase in hidden states, identifying layers that contribute little new information compared to geometric similarity metrics.
Core Problem
Large Language Models are computationally expensive, but existing pruning methods rely on cosine similarity, which measures geometric alignment rather than actual information richness.
Why it matters:
- LLMs scale to billions of parameters, creating massive storage and compute demands for deployment
- Existing metrics like cosine similarity may misidentify redundant blocks, leading to suboptimal pruning decisions that degrade model accuracy
- Attention blocks in particular are highly redundant but computationally expensive
Concrete Example:
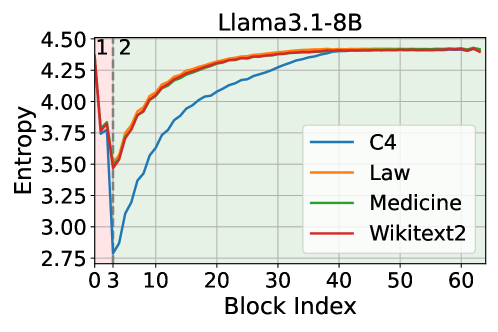
In layers 3-32 of Llama-3.1-8B, entropy gradually increases. A cosine-based method might keep a layer because its output vector is geometrically distinct, even if its entropy change is minimal (meaning it adds little new information/uncertainty reduction).
Key Novelty
Entropy-Based Block Pruning (EntroDrop)
- Analyzes information flow via entropy dynamics: early layers compress information (entropy decreases), while later layers enrich it (entropy increases)
- Uses entropy increase as a direct proxy for 'information contribution'; layers with minimal entropy increase in the enrichment stage are deemed redundant and pruned
- Replaces the de facto cosine similarity metric with entropy estimation (bucket-based or KNN) for more reliable redundancy detection
Architecture
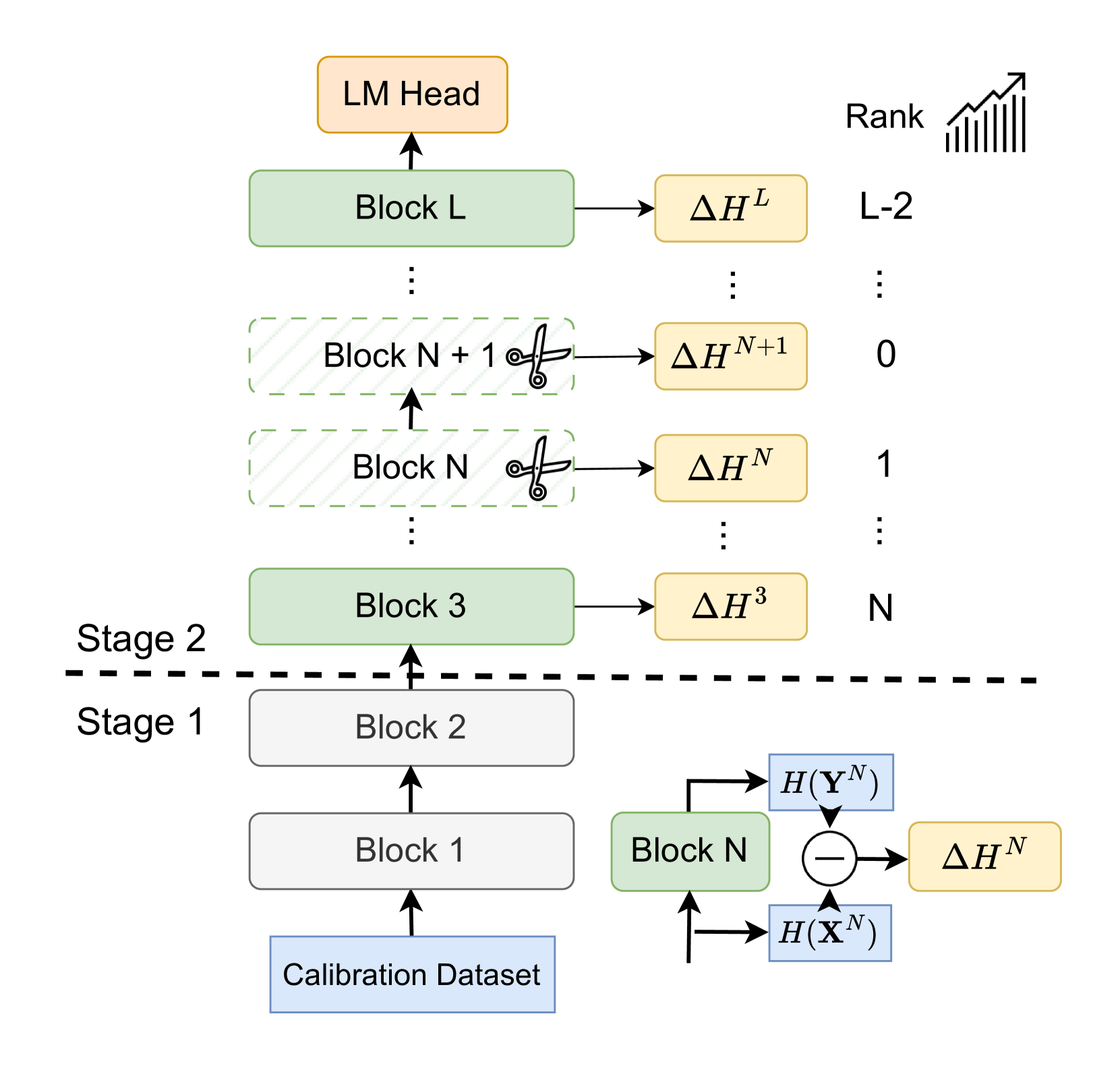
The EntroDrop framework pipeline. It illustrates the process of feeding calibration data, estimating entropy per block, ranking blocks by entropy increase, and pruning the least informative ones.
Evaluation Highlights
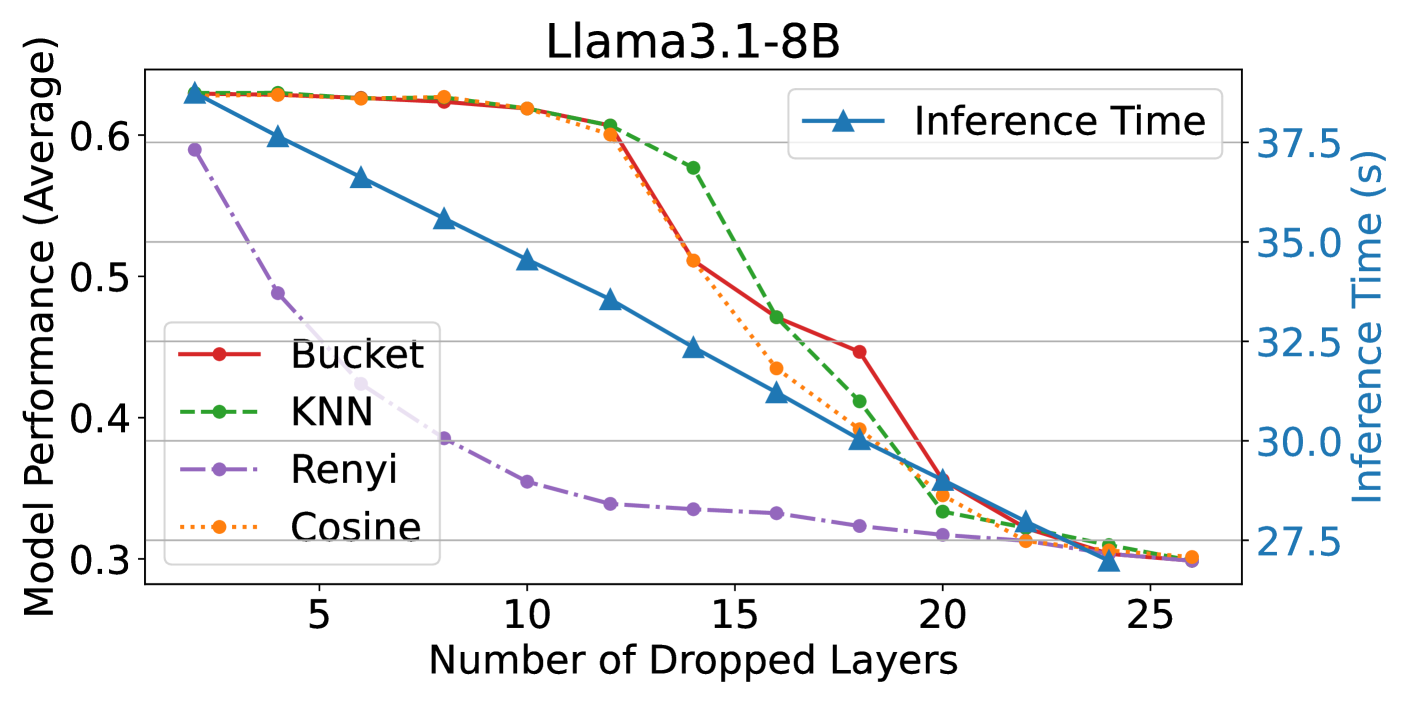
- Removing 12 attention layers (37.5% of total) in Llama-3.1-8B retains >95% of original performance across multiple benchmarks
- Outperforms cosine similarity-based baselines (ShortGPT, LaCo, LLMDrop) on MMLU and reasoning tasks while reducing inference latency
- Inference speed increases linearly with pruning; removing 12 layers provides significant speedup with minimal accuracy loss
Breakthrough Assessment
7/10
Offers a theoretically grounded shift from geometric (cosine) to information-theoretic (entropy) pruning metrics. Strong empirical results on modern LLMs, though the method is a refinement of existing block pruning rather than a new architecture.