📝 Paper Summary
Agentic RAG pipeline
Single-cell genomics analysis
ELISA integrates transcriptomic foundation model embeddings with semantic text retrieval via an adaptive routing mechanism to enable interpretable, natural-language discovery in single-cell genomics without retraining.
Core Problem
Agentic AI systems excel at text reasoning but lack access to transcriptomic data structure, while expression foundation models (like scGPT) capture cellular representations but are opaque to natural language queries.
Why it matters:
- Translating statistical outputs (differential expression, pathways) into mechanistic biological hypotheses is currently labor-intensive and difficult to reproduce
- Existing agents operate on curated text/databases and cannot query raw high-dimensional expression data
- Expression foundation models are not designed for semantic querying, creating a disconnect between latent spaces and biological concepts
Concrete Example:
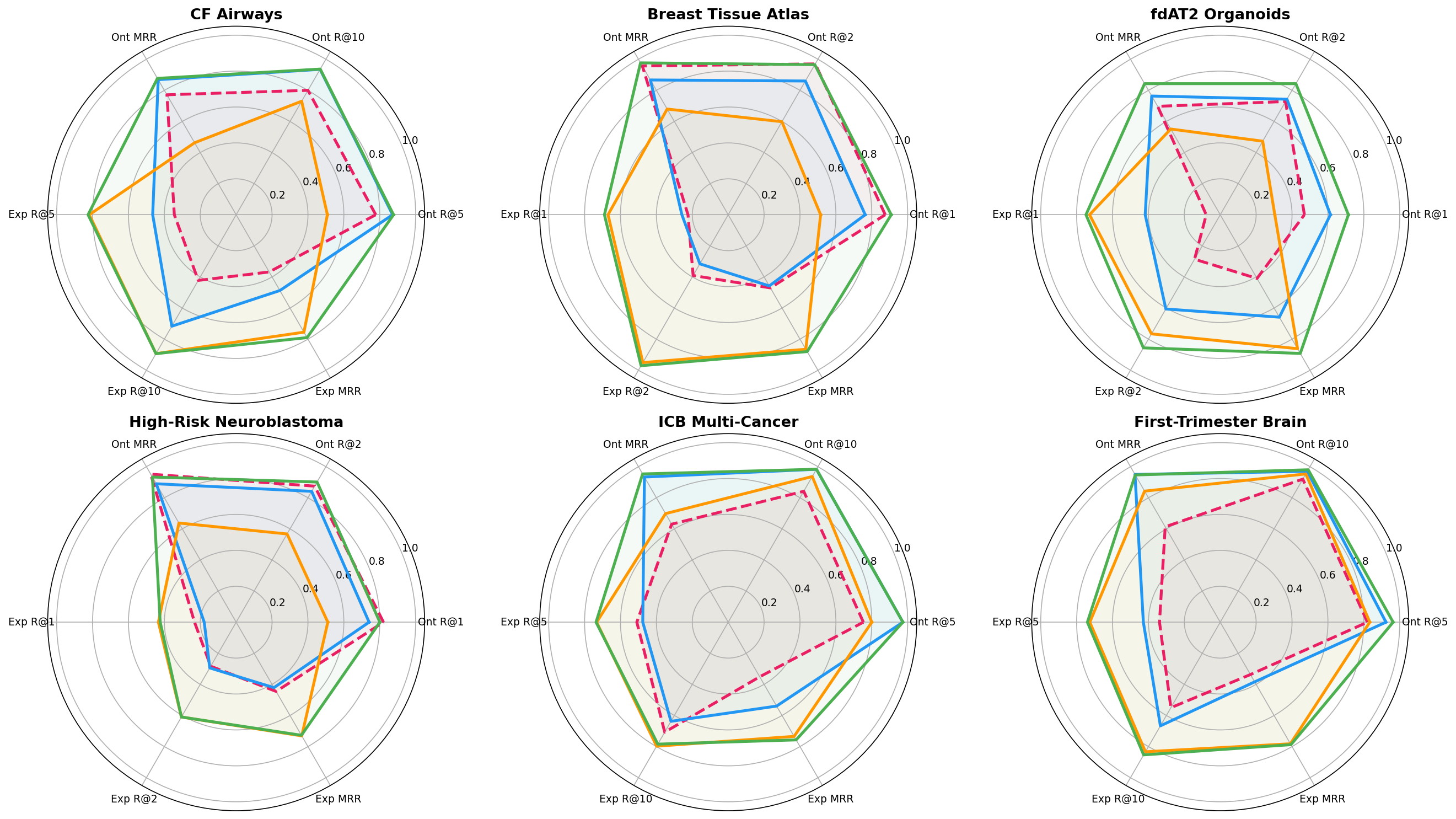
When a researcher queries a gene signature like 'MARCO FABP4 APOC1...', text-aligned models like CellWhisperer fail (MRR ~0.40) because they optimize for natural language descriptions, ignoring the explicit expression signal that ELISA's gene-scoring pipeline captures (MRR ~0.81).
Key Novelty
Embedding-Linked Interactive Single-cell Agent (ELISA)
- Unifies scGPT expression embeddings and BioBERT semantic embeddings in a shared representation without retraining, enabling dual-modality access
- Employs an automatic query classifier to route inputs to the optimal retrieval pipeline: gene marker scoring for signatures, semantic similarity for concepts, or reciprocal rank fusion for mixed queries
Architecture
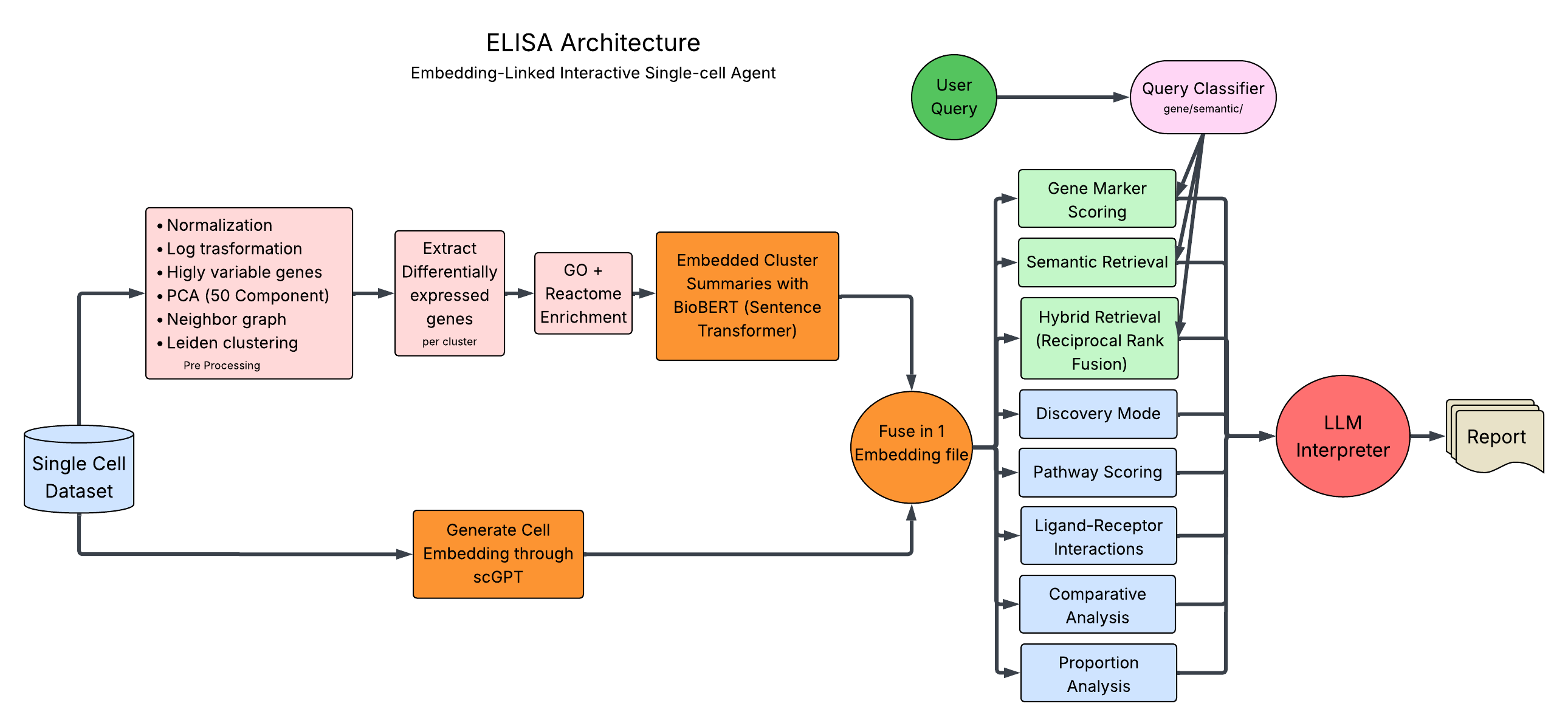
The complete ELISA framework showing how user queries are routed, retrieved, analyzed, and interpreted.
Evaluation Highlights
- Significantly outperforms CellWhisperer in cell type retrieval (combined permutation test, p<0.001) across six datasets
- Achieves massive gains on gene-signature queries (Cohen’s d = 5.98 for MRR) by leveraging dedicated expression scoring
- Replicates published biological findings with high fidelity (mean composite score 0.90), including near-perfect pathway alignment (0.98)
Breakthrough Assessment
8/10
Bridging the gap between expression foundation models and semantic agents is a significant architectural advance for scientific AI. The retrieval gains on expression queries are drastic.