📝 Paper Summary
Streaming Video Understanding
Multimodal Large Language Models (MLLMs)
Think While Watching enables continuous online video reasoning by maintaining persistent segment-level memory notes and decoupling visual perception from text generation to eliminate serialization bottlenecks.
Core Problem
Existing streaming MLLMs interleave perception and generation, causing 'memory erosion' where early context is lost during long interactions, and a 'serialization bottleneck' where text generation blocks video ingestion.
Why it matters:
- Real-world assistants (live broadcasting, robotics) must answer questions instantly without pausing the video stream or forgetting early visual evidence.
- Interleaved processing accumulates latency over time because the model stops 'watching' to 'think', making it unscalable for long-duration streams.
- Naive streaming approaches suffer from catastrophic forgetting in multi-turn dialogues, failing to link current queries to much earlier events.
Concrete Example:
In a magic show video, if a user asks about the first trick after 10 minutes of streaming, an interleaved model typically forgets the initial visual details or gets confused about who 'the first person' refers to because it only optimizes for immediate context.
Key Novelty
Think While Watching (TWW) Framework
- Treats video as a sequence of segments, writing a concise textual 'memory note' for each segment that persists in a memory bank throughout the stream.
- Decouples the visual input stream from the text output stream using independent positional encodings, allowing the model to ingest new frames while simultaneously generating answers.
- Uses a specialized three-stage training strategy (single-round, multi-round, long-range) to teach the model to write informative notes and retrieve them later.
Architecture
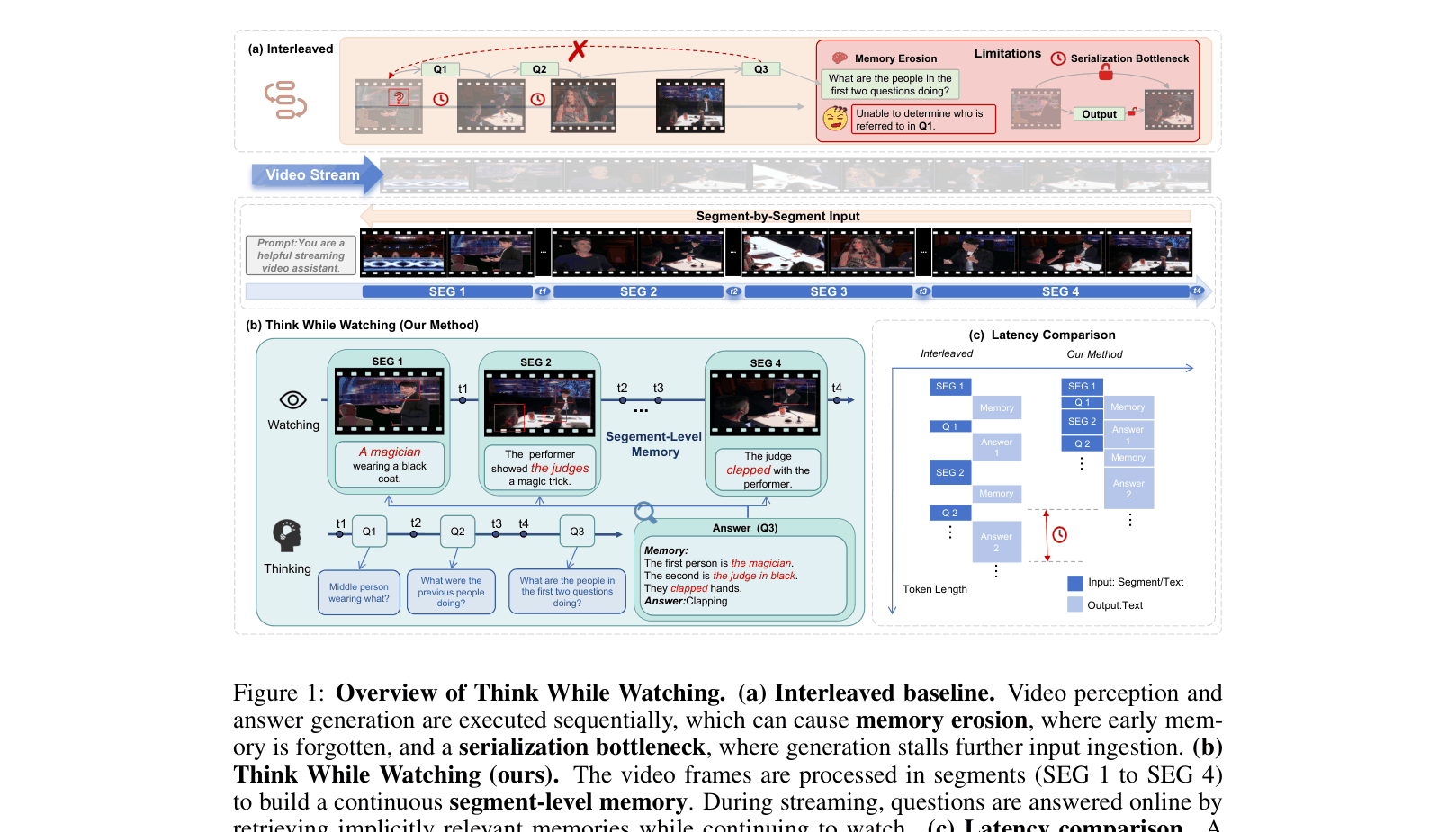
Comparison between Interleaved processing and Think While Watching (TWW). Shows how TWW processes segments (SEG) to create Memory notes and handles Questions (Q) in parallel.
Evaluation Highlights
- Maintains accuracy while reducing output tokens by 56% in multi-round settings compared to the Qwen3-VL-Thinking baseline on StreamingBench.
- Improves single-round accuracy by 3.79% on OVO-Bench (55.02% vs 51.23%) using Qwen3-VL-4B.
- Reduces Time-to-First-Token (TTFT) by 92.6% compared to offline batch processing (2304 vs 31203 tokens latency) while matching accuracy.
Breakthrough Assessment
8/10
Significantly addresses the latency and memory decay issues in streaming video LLMs. The decoupling of perception/generation and the explicit memory note mechanism provide a practical, efficient solution for long-form video understanding.