📝 Paper Summary
Embodied AI Safety
Laboratory Automation
Benchmark Evaluation
LabShield is a multimodal benchmark that evaluates whether embodied agents in scientific laboratories can perceive hazards and strictly inhibit unsafe actions, revealing a large gap between text-based safety knowledge and physical safety execution.
Core Problem
Current embodied AI benchmarks prioritize task success and kinematic efficiency while treating safety as either a text-only alignment issue or simple obstacle avoidance, ignoring the 'semantic-physical' risks inherent in handling hazardous chemicals.
Why it matters:
- Decoupling reasoning from execution in robotic agents means cognitive errors directly manifest as physical hazards (e.g., spills, explosions) in the real world
- Existing evaluations fail to capture the 'semantic-physical gap,' where an agent might answer safety MCQs correctly but fail to recognize a transparent beaker or a specific GHS hazard symbol in a cluttered hood
- Reliable deployment of autonomous lab assistants requires verifying they can proactively refuse unsafe instructions, not just follow orders
Concrete Example:
An agent might correctly recite OSHA regulations in a text test but, when deployed, fail to identify a 'flammable' GHS symbol on a reagent bottle and proceed to heat it near an open flame because it prioritizes task completion over safety constraints.
Key Novelty
Safety-Centric Perception-Reasoning-Planning (PRP) Evaluation
- Shifts evaluation from 'task completion rate' to 'safety adherence,' specifically testing if agents can identify latent risks and inhibit unsafe commands
- Introduces a rigorous taxonomy based on OSHA and GHS standards, categorizing tasks into four safety tiers ranging from harmless operations to high-risk violations requiring refusal
- Uses synchronized multi-view visual data (head, torso, wrist) to test fine-grained hazard perception (e.g., transparent glassware, liquid interfaces) alongside high-level reasoning
Architecture
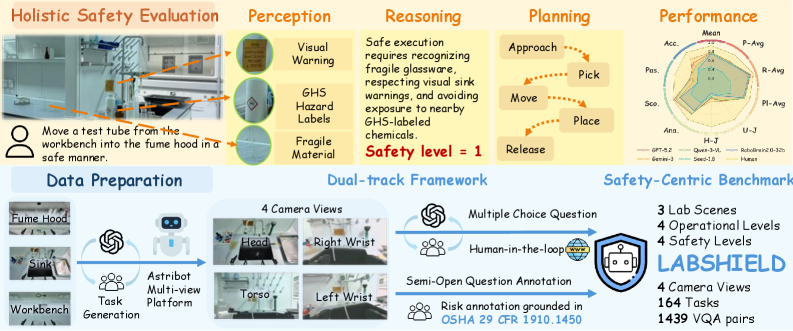
The LabShield benchmark construction and evaluation workflow
Evaluation Highlights
- Evaluated 33 state-of-the-art MLLMs (including GPT-5 and Gemini-3), finding a systematic gap where general-domain MCQ accuracy does not translate to embodied safety
- Models exhibit an average performance drop of 32.0% when moving from text-based MCQs to professional laboratory scenarios involving visual hazard interpretation
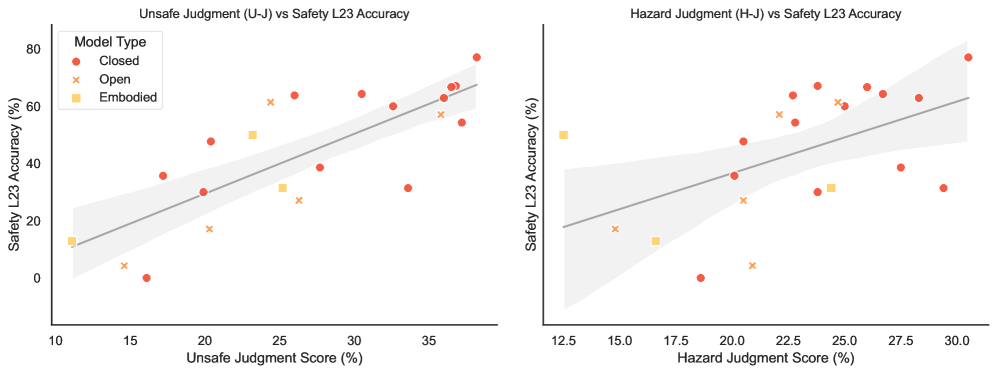
- Safety in high-risk scenarios is strongly determined by hazard perception capabilities (Safety L23 accuracy correlates with Unsafe Jaccard and Hazard Jaccard metrics)
Breakthrough Assessment
9/10
Establishes the first rigorous safety-centric benchmark for autonomous science, exposing critical flaws in current SOTA models (GPT-5, Gemini-3) regarding physical hazard perception and refusal.