📝 Paper Summary
Personalized Federated Learning (PFL)
Multi-Objective Optimization
FedFew solves the scalability-personalization trade-off in federated learning by maintaining a small set of shared server models that are jointly optimized via smoothed Tchebycheff scalarization to cover the Pareto front of client objectives.
Core Problem
Standard Federated Learning fails on heterogeneous data, while full personalization (one model per client) is unscalable; existing compromises like clustering lack theoretical optimality guarantees.
Why it matters:
- In domains like healthcare or finance, data distributions (e.g., patient demographics) vary wildly, meaning a single global model cannot serve all clients effectively.
- Existing multi-objective methods typically find only a single trade-off solution rather than personalized optima for each client.
- Heuristic methods (like clustering) create non-convex, discontinuous landscapes that are difficult to optimize with gradient descent.
Concrete Example:
In a healthcare federation, urban and rural hospitals have conflicting data distributions. Optimizing a single model for urban demographics harms rural performance. Conversely, training separate models for thousands of hospitals is computationally prohibitive. FedFew identifies a small set (e.g., 3) of shared models that cover these distinct groups automatically.
Key Novelty
Few-for-Many (K-for-M) Optimization Framework
- Reformulates Personalization as finding a small set of K models to serve M clients (K << M), proving that approximation error vanishes as K increases.
- Uses 'Two-Level Smoothing' to transform the discrete, non-differentiable problem of assigning clients to models into a smooth objective, allowing efficient gradient-based optimization of both model parameters and assignments.
- Replaces manual clustering heuristics with a principled multi-objective optimization approach (Tchebycheff scalarization) that guarantees Pareto stationarity.
Architecture
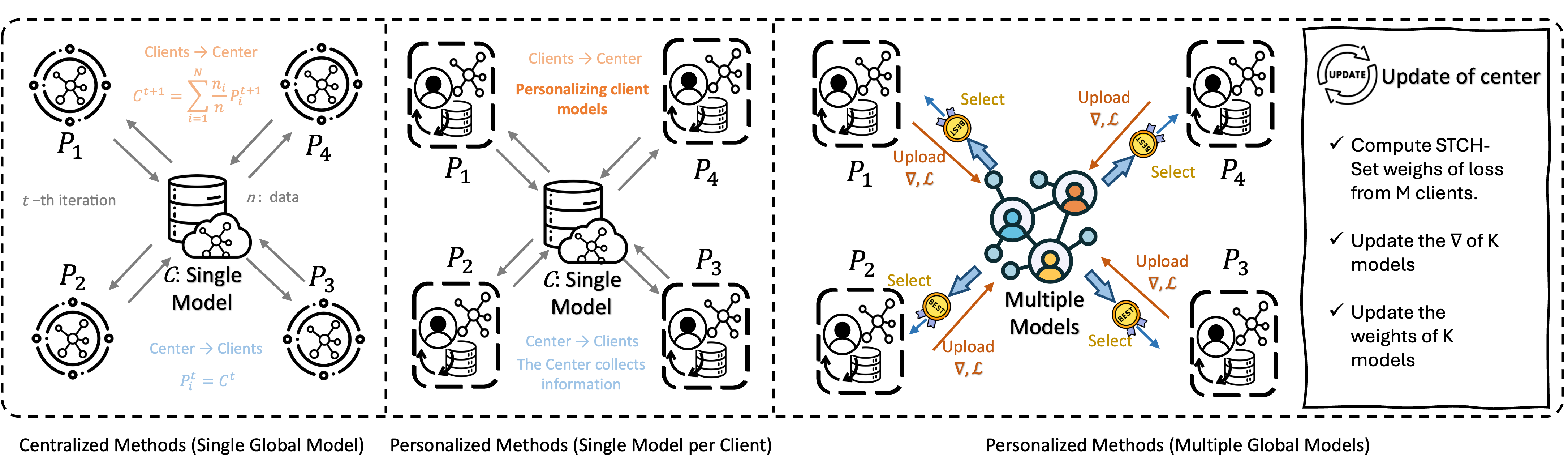
Illustration of the K-for-M framework where K shared server models collectively serve M clients.
Breakthrough Assessment
8/10
Provides a rigorous theoretical foundation (Pareto coverage guarantees) for a problem often solved by heuristics, combined with a practical algorithm that makes discrete model selection differentiable.